Lab 6 - Tablice haszujące i typy napisowe¶
Tablice haszujące¶
Teoria¶
Interfejs¶
System typów Pascala czyni implementację pewnych struktur danych, w tym tablic haszujących, dość kłopotliwą. Nie bardzo bowiem widać, w jaki sposób można uzyskać słownik, zbiór, stos czy listę, które mogłyby przechowywać dane różnych typów - liczby, napisy, rekordy itp. Istnieją kilka podejść do tego problemu:
- Można skopiować implementację i stworzyć osobne wersje dla każdego typu - z oczywistych względów taka redundancja jest jednak bardzo nieporządana.
- Można też skorzystać z preprocesora - dzięki temu kompilator sam wygeneruje kopie implementacji. Sposób takie (nad)użycia mechanizmu makr jest opisany na stronie http://wiki.freepascal.org/Templates
- Nowsze wersje FPC obsługują pewien wariant typów parametryzowanych, ale mechanizm ten jest jeszcze bardzo niedopracowany.
- Innym rozwiązaniem są nieotypowane wskaźniki (tz. typu Pointer). Korzystanie z nich wymaga rzutowania na prawdziwy typ przechowywanych wartości. Podobny mechanizm był stosowany w Javie przed wersją 1.5 (z tym, że tam poprawność rzutowania była w czasie wykonania sprawdzana, podczas gdy Pascal zinterpretuje dowolny kawałek pamięci jako dowolny typ). Przy tym podejściu trzeba jednak uważać na liczne pułapki - oprócz oczywistej możliwości pomyłki przy rzutowaniu musimy uwzględnić np. problemy z typami stosującymi zliczanie referencji (w tym AnsiString) - po zrzutowaniu na nieotypowany wskaźnik mechanizm ten przestaje działać.
Przyjmijmy ostatnie z proponowanych rozwiązań. Moduł tablic haszujących może mieć np. taki interfejs:
unit Hashtable;
{$mode objfpc}{$H+}
interface
type
THashFunction = function(Key : Pointer) : LongInt;
TEqualsFunction = function(Key, Key2 : Pointer) : LongInt;
THashTable = record
{ ... }
end;
procedure HashtableInit(var T : THashTable;
HashFunction : THashFunction;
EqualsFunction : TEqualsFunction);
procedure HashtableFree(var T : THashTable);
procedure HashtableInsert(var T : THashTable;
Key : Pointer;
Value : Pointer);
function HashtableFind(const T : THashTable;
Key : Pointer) : Pointer;
function HashtableContains(const T : THashTable;
Key : Pointer) : Boolean;
implementation
{ ... }
end.
Nie znamy rzeczywistego typu kluczy, więc nie możemy podać sposobu ich porównywania ani konkretnej funkcji haszującej. Te procedury musi podać użytkownik przy tworzeniu tablicy (metoda HashtableInit). Ptzyjmujemy, że funkcje haszujące (typ THashFunction) zwracają dowolną liczbę całkowitą - przycięcie jej do rozmiaru tablicy jest już zadaniem omawianego modułu. Zauważmy też, że przy zwalnianiu tablicy nie możemy zwolnić pamięci wskazywanej przez klucze czy wartości - bo jest możliwe, że są do niej jeszcze inne odwołania. Albo, że wskaźniki wcale nie są wskaźnikami tylko po prostu liczbami (IntPtr).
Funkcje haszujące¶
Własności funkcji haszujących to niezwykle rozległy temat. Omówienie go, choćby pobieżnie, w ramach zajęć z IPP nie jest raczej możliwe. Poprzestańmy więc na podaniu przykładowej funkcji haszującej napisy.
function FNV(Key : Pointer) : LongInt;
var
Str : AnsiString;
Hash : LongInt;
i : Integer;
begin
Str := AnsiString(Key);
Hash := -2128831035;
for i := 1 to Length(Str) do
begin
Hash := Hash xor Ord(Str[i]);
Hash := Hash * 16777619;
end;
Result := Hash;
end;
Zauważmy, że funkcja ta bierze, zgodnie z wcześniej podanym interfejsem, nieotypowany wskaźnik jako parametr. Jego faktycznym typem powinien być typ AnsiString, omówiony w dalsej części notatek.
Implementacja¶
Ostrzeżenie
Implementacja jest ćwiczeniem do wykonania w czasie laboratorium.
Typy napisowe¶
Shortstring¶
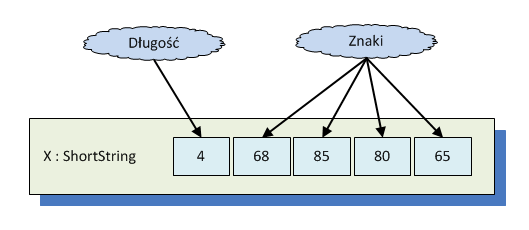
W Pascalu tradycyjnie implementuje się typy napisowe jako tablice bajtów, w których wartość pierwszego elementu wyznacza długość napisu, zaś pozostałe reprezentują kody kolejnych znaków. Ten prosty mechanizm ma jednak pewne wady:
- Z oczywistych względów maksymalną długością napisu jest 255.
- Przypisanie wiąże się zawsze z kopiowaniem całego napisu.
- Nie ma mechanizmu pozwalającego na określenie kodowania. Utrudnia to znacząco porównywania i sortowanie napisów. Trzeba też zauważyć, że 256 możliwych znaków to za mało dla niektórych standardów kodowania.
PChar¶
W języku C najprostszą fromą reprezentacji napisu jest wskażnik do pamięci zawierającej ciąg znaków zakończony bajtem o wartości zero. Free Pascal pozwala operować na takich strukturach za pomocą funkcji z modułu strings. Główne różnice między napisami w stylu C (typ PChar) a tradycyjnymi napisami Pascalowymi to:
- Napis jest reprezentowany przez wskaźnik, więć trzeba ręcznie zarządzać pamięcią - np. alokować ją za pomocą funkcji stralloc i zwalniać przez strdispose.
- Nie ma ograniczenia na długość napisu, ale funkcja licząca ową długość (strlen) działa w czasie liniowym. Łatwo jest popełnić błąd i wygenerować napis bez kończącego zera, co może mieć groźne następstwa dla bezpieczeństwa aplikacji.
- Napis nie może zawierać znaków o kodzie równym zero.
- Biblioteka zawiera funkcje porównujące napisy z uwzględnieniem skonfigurowanego w systemie języka.
- Proste przypisanie na zmienną napisową powoduje skopiowanie wskaźnika, a nie całej wartości napisu. Może to oczywiście powodować problemy z aliasowaniem.

Ansistring¶
Typ Ansistring łączy cechy typów PChar i Shortstring. Podobnie jak w przypadku PChar jest wskaźnikiem. Jednak w wskazywanej pamięci, przed znakami tworzącymi napis, przechowywana jest jego długość - w postaci 32-bitowej (lub 64-bitowej) liczby. Na końcu napisu zawsze jest umieszczany bajt o wartości zero, ale takie bajty mogą też występować w innych miejscach. Oprócz długości Ansistring przechowuje również licznik referencji. Dzięki temu nie ma konieczności ręcznego zarządzania pamięcią. Przypisanie powoduje skopiowanie wskaźnika (jak w PChar) i zwiększenie licznika referencji. Treść napisu zostanie skopiowana dopiero przy pierwszej próbie modyfikacji jego treści - usuwa to problem z aliasowaniem przy zachowaniu efektywnej implementacji przypisania z typu PChar w sytuacjach, gdy po przypisaniu napis nie jest zmieniany.
Reprezentacja napisu pustego jest nieco inna - konkretnie jest to wskaźnik równy nil. Może to mieć znaczenie np. przy rzutowaniu z typu AnsiString na typ Pointer.
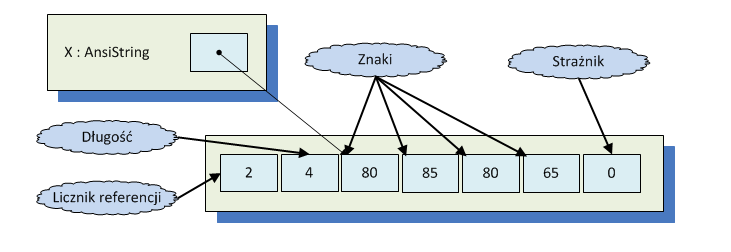
Free Pascal w wersji 2.7.1 przechowuje dodatkowo przy każdym napisie jego kodowanie - ale większość funkcji bibliotecznych ignoruje tę informację.
Dyrektywa kompilatora {$H+} powoduje zastapenie typu String przez AnsiString. Podobny efekt daje włączenie trybu Delphi (np. przez {$mode delphi}).
Unicode¶
Istnienie wielu standardów kodowania znaków (często kilku dla jednego języka lub alfabetu) stanowi dużą niedogodność przy tworzeniu programów operujących na napisach. Stąd też powstał pomysł stworzenia jednego kodowania opisującego znaki wszystkich znanych alfabetów oraz wszelkie inne symbole, które mogą wsytępować w tekście. W efekcie powstał standard Unicode. Niestety jego istnienie nie rozwiązuje wszystkich problemów związanych z operacjami na tekście (a anwet tworzy trochę nowych).
Unicode zawiera zbyt dużo znaków, by kod jednego z nich dałó się zmieścić w jednym czy dwóch bajtach. W efekcie istnieje kilka sposobów reprezentacji napisów:
- UTF32 - każdy znak zajmuje cztery bajty.
- UTF16 - większośc znaków zajmuje jedno, dwubajtowe słowo, ale niektóre znaki są prerezentowane przez parę slów.
- UTF8 - znaki reprezentowane są przez sekwencje bajtów. Górne bity pierwszego bajtu opisują długość sekwencji. Dla znaków o kodach < 127 kodowanie UTF8 jest identyczne z ASCII.
Pierwsze dwa warianty występują w dwóch wersjach - big endian i liitle endian - w zależności od porządku bajtów w słowie.
Dla ułatwienia wykrycia sposobu kodowania na początku zawartości pliku umieszcza się znacznik BOM - program przetwarzający plik nie powinien traktować tego znacznika jak części treści.
Oprócz liter, cyfr i podobnych znaków Unicode zawiera też kilka innych klas symboli, w tym
- Separatory paragrafów, puste odstępy i inne, niewidoczne znaki.
- Akcenty i inne modyfikatory - pozwalają np. dokleić ogonek do poprzedzjącej litery.
- Znaczniki kierunku tekstu - ten sam napis może zawierać fragmenty pisane od lewej do prawej i odwrotnie.
Unicode oferuje więc dużą siłe wyrazu, jednak ceną za to jest bardzo skomplikowane przetwarzanie napisów. Nie można porównać ich bajt po bajcie, bo ten sam znak może być reprezentowany na wiele sposobów. Na przykład literę ‘ą’ można zapisać jednym znakiem lub też użyć ‘a’ i stosownego akcentu. Jeśli do znaku zastosowano kilka modyfikatorów, nie jest jasne, kiedy ich kolejność ma znaczenie. Gdybyśmy zaś oprócz prostego zbadania identyczności chcieli napisy sortować, pojawią się jeszcze poważniejsze problemy - Unicode opisuje znaki wszystkich alfabetów, ale nie zmienia to faktu, że w różnych językach te same znaki trzeba sortować w różnej kolejności. Przykładowo:
- W języku szwedzkim litery z akcentem występują po ‘Z’ - czyli z < ö.
- W niemieckim inaczej sortuje się zawartość słowników, a inaczej książek telefonicznych. W pierwszym przypadku ö występuje bezpośrednio po o, a w drugim - przed.
- W pewnym kraju na zachodzie Europy najpierw porównuje się słowa ignorując akcenty, a jeśli nie ma różnic, decyduje ostatnia z różnie akcentowanych liter [1].
Standard Unicode zmienia się od czasu do czasu, więc większość implementacji jest nieaktulna.
Free Pascal udostępnia dwa typy związanie z Unicode - UnicodeString i Utf8String. Pierwszy jest podobny do AnsiString, ale używa dwubajtowych znaków (UTF-16). Funkcje do porównywania wartości i podobnych operacji korzystają z operacji zdefiniowanych w obiekcie typu TUnicodeManager. Pascal inicjalizuje ten obiekt w sposób zależny od systemu operacyjnego.
Typ Utf8String jest, w obecnej (2.6) wersji FPC zwykłym aliasem dla Ansistring. Zdefiniowane są funkcje konwertujące UnicodeString na Utf8String i w drugą stronę.
Ostrzeżenie
Lazarus wymaga stosowania typu Utf8String dla napisów stanowiących część interfejsu użytkownika.
W praktyce aplikacje, w których istotna jest poprawna obsługa Unicode, korzystają zwykle z biblioteki ICU (http://site.icu-project.org/). Interfejs dla Delphi/FPC nazywa się ICU4PAS (http://www.crossgl.com/icu4pas/).
Przypisy
| [1] | Nie napiszę, który to kraj, ale gdyby ktoś odwiedzał jego stolicę, to radzę uważać, bo na stacji RER koło Ogrodu Luksemburskiego kradną okulary. |