Pobieżne wprowadzenie do podstaw części C#, Tom I, Część I
v1.1.1 Copyright © Mateusz Gienieczko 2019-2020
0. Plan.
- Plan.
- Co to C#/.NET (Framework/Core/Standard)/CLR/ABC/XYZ?
- Jak poprawnie C#?
- “Yyy, na MIMie nie uczą o SOLID!!!1”
- Jak działa ASP .NET?
- Jak działa Entity Framework?
- Przykładowa apka.
1. Co to C#/.NET(Framework/Core/Standard)/…?
C# (obecnie 7.3) - język zaprojektowany w 2000 przez Andersa Hejlsberga dla Microsoftu.
Roslyn - główny kompilator C#, open-source.
CLI (Common Language Infrastructure) - specyfikacja środowiska i bytecode’u do uruchamiania między innymi C#. Taka lepsza JVM.
-
CLR (Common Language Runtime) - środowisko
-
CIL (Common Intermediate Language, w skrócie IL) - bytecode, taki pseudo-assembler
.assembly Hello {}
.assembly extern mscorlib {}
.method static void Main()
{
.entrypoint
.maxstack 1
ldstr "Hello, world!"
call void [mscorlib]System.Console::WriteLine(string)
ret
}
Oczywiście nikt normalny w tym nie pisze. Więcej IL-a już nie będzie, I promise. Czasami jednak może pojawić się stwierdzenie “powyższe dwa kody produkują równoważny IL”, co będzie oznaczać, że jedna z wersji jest po prostu lukrem syntaktycznym tłumaczonym przez kompilator w locie i nie ma wpływu na kod wykonywalny.
Managed code - kod uruchamiany na CLR.
Unmanaged code - zewnętrzny kod (albo unsafe), np. wywołana biblioteka w C++.
JIT Compiler (Jitter) - kompilator Just-In-Time, kompiluje IL do języka maszynowego at runtime.
.NET Framework (obecnie 4.7.3) - wielka biblioteka do języków uruchamianych w CLR, w tym C#. Działa tylko pod Windowsem.
.NET Core (obecnie 2.2, 3.0 w drodze) - analogicznie wielka biblioteka, ale wieloplatformowa i open-source.
.NET Standard (obecnie 2.0) - standard, który musi spełniać każda implementacja .NETa, jest więc podzbiorem przecięcia Frameworka i Core’a. Obejmuje np. podstawowe kolekcje.
2. Jak poprawnie C#?
C# jest obiektowym, statycznie typowanym, kompilowanym językiem. Ma też najdłuższą listę obejmowanych paradygmatów jaką w życiu widziałem na Wikipedii. Jest imperatywny, deklaratywny, obiektowy, funkcyjny, generyczny, współbieżny, zajebisty i zapewne istnieje do niego biblioteka, która parzy kawę. It truly embraces the general purpose label.
C# jest zorientowany na bezpieczeństwo i wygodę developera. Tak długo, jak poruszamy się po świecie CLR-managed kodu najgorsze co może nas spotkać to NullReferenceException albo błąd logiki. Nie da się zaorać sobie kawałka pamięci, zapomnieć coś zwolnić, a momenty, w których krzyczymy na język, że jest upośledzony (vide Java) oraz takie, w których język krzyczy na nas, że jesteśmy za głupi (vide C++), są ograniczone do minimum. C# ma też wspaniałe środowisko w postaci tandemu VisualStudio + ReSharper.
Nawet wtedy pozwala nam porzucić granice zdrowego rozsądku i udostępnia typowanie dynamiczne (dynamic) oraz magiczny keyword unsafe, który wyłącza memory safety, GC, ABS i wspomaganie kierownicy.
W tej prezentacji jednak nie będziemy poza rzeczone granice wychodzić.
2.1 Klasyka gatunku
namespace SeeITSharp
{
public class HelloWorld
{
public static void Main()
{
System.Console.WriteLine("Hello World!");
}
}
}
- Nazwy namespace’ów, klas i metod piszemy CamelCasem.
- Każda klasa musi należeć do namespace’a.
- Każda metoda musi należeć do klasy.
Mainmoże przyjmować tablicę argumentów albo i nie oraz zwracaćinta albo i nie.
public static int Main(string[] args)
2.2 Assembly i namespace’y
Pojedyncza jednostka kompilacji w świecie .NET-u to assembly. Skompilowane assembly ma rozszerzenie .dll w przypadku bibliotek, a .exe w przypadku wykonywalnych aplikacji (czyli takich z Mainem).
W obrębie danego assembly możemy mieć wiele namespace’ów. Można o tym myśleć jak o strukturze katalogów - katalog nadrzędny to nazwa assembly, każdy kolejny zagnieżdżony namespace to podkatalog. Kolejne namespace’y oddzielamy kropką.
namespace SeeITSharp.MyNamespace.MySubnamespace
{
class HelloWorld
{
/*...*/
}
}
Do powyższej klasy można odwołać się tzw. nazwą kwalifikowaną, zawierającą wszystkie namespace’y, czyli SeeITSharp.MyNamespace.MySubnamespace.HelloWorld. Można jednak pominąć nadrzędne namespace’y, a najlepiej użyć dyrektywy using.
using System;
namespace SeeITSharp
{
class HelloWorld
{
Console.WriteLine("Hello World!"); // This is actually System.Console being called.
}
}
> Hello World!
2.3 Podstawowe typy
Podstawowe funkcjonalności języka są podobne jak w Javie. Mamy garść typów wbudowanych:
bool-true,false;byte- 8 bitów;sbyte- 8 bitów ze znakiem;char- 16 bitów do przechowywania znaku w Unicode;decimal- 128 bitów z wysoką precyzją np.1234.5678m;double- 64 bity, double precision floating point np.1234.5678;float- 32 bity floating point np.1234.5678f;int- 32 bity ze znakiem;uint- 32 bity bez znaku;long- 64 bity ze znakiem;ulong- 64 bity bez znaku;object- korzeń hierarchii dziedziczenia wszystkich typów referencyjnychshort- 16 bitów ze znakiem;ushort- 16 bitów bez znaku;string- napis.
Mamy też tablice:
int[] tab = new int[16];
for (int i = 0; i < tab.Length; ++i)
{
tab[i] = i;
}
for (int i = 0; i < tab.Length; ++i)
{
Console.Write(i.ToString() + " ");
}
Console.WriteLine();
> 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Wielowymiarowe tablice występują w dwóch smakach: multidimensional arrays oraz jagged (z ang. poszarpany) arrays.
int[][] jagged = new int[4][];
for(int i = 0; i < jagged.Length; ++i)
{
jagged[i] = new int[i + 1];
}
int[,] multi = new int[4, 4];
jagged[1][1] = 1;
multi[1, 1] = 1;
Console.WriteLine(jagged[1][1]);
Console.WriteLine(multi[1, 1]);
> 1
> 1
Jagged to tablica tablic, multidimensional to pojedyncza tablica z magią w środku. Multidimensional powinno się używać tylko wtedy, kiedy rzeczywiście operujemy na prostokątach (vel prostopadłościanach w N wymiarach). Jagged zawsze wtedy, kiedy możemy mieć np. różne liczby kolumn dla każdego wiersza.
2.4 Keyword var
C# jest statycznie typowany, ale niekoniecznie explicitly typowany. Posiada local variable type inference, tzn. kompilator jest w stanie wywnioskować typ deklaracji na podstawie przypisania.
int i = 3;
var i = 3;
Obie powyższe deklaracje poskutkują identycznym kodem IL. Po prawej stronie nie musi stać literał.
var line = Console.ReadLine(); // Variable line is a string.
Istnieją różne konwencje używania var. Bodajże najpopularniejsza głosi “używaj var zawsze wtedy, kiedy typ po prawej jest widoczny na pierwszy rzut oka.” Ja sam posługuję się konwencją “używaj var zawsze”. Jednakże w jednym wszystkie konwencje są zgodne - wbudowane typy to zawsze var. Wszelkie inty, stringi itp. zamieniamy na var.
2.5 Pętla foreach
Do iterowania się po tablicach, (dokładniej po IEnumerable, o którym później), w większości przypadków używa się pętli foreach.
int[] tab = new int[16];
for (int i = 0; i < tab.Length; ++i)
{
tab[i] = i;
}
foreach(var i in tab)
{
Console.Write(i.ToString() + " ");
}
Console.WriteLine();
> 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2.6 Access specifiers
Zajmijmy się w końcu klasami. W C# mamy cztery/sześć access specifiery, zależy pod jakim kątem spojrzeć.
public- widoczne wszędzie (jak w Javie)internal- widoczne w obrębie tego assembly (podobne do package-private w Javie)protected- widoczne dla mnie i wszystkiego, co po mnie dziedziczy (jak w Javie)private- widoczne dla mnie i tylko dla mnie (jak w Javie)
Dodatkowo istnieją dwie wariacje:
protected internal- widoczne w obrębie tego assembly oraz dla wszystkiego, co po mnie dziedziczy (także w innym assembly)private protected- widoczne tylko w obrębie tego assembly, tylko dla mnie i tego co po mnie dziedziczy
Dwa ostatnie przydają się sporadycznie.
2.7 Enums
Enumy w C# nie różnią się niczym specjalnym od tych w innych językach.
public enum Color
{
Red,
Yellow,
Green,
Blue,
Black
}
var color = Color.Red;
Enum jest tak naprawdę zmienną innego typu przebraną za enum. Tym typem domyślnie jest int i da się to zmienić, można też ustawić domyślne wartości.
public enum Color : short
{
Red = 1,
Yellow = 2,
Green = 4,
Blue = 8,
Black = 16
}
var mix = Color.Red | Color.Yellow | Color.Black;
Console.WriteLine((int)mix);
> 19
2.8 Fields
Pola wewnątrz klasy deklaruje się jak w Javie.
public class RubberDuck
{
private int _timesSqueaked = 0;
private readonly string _name;
private static const Color Color = Color.Yellow;
}
Pola mogą mieć domyślne wartości, tak jak wyżej.
Mogą one mieć dodatkowe modyfikatory.
readonly- to pole może być ustawione tylko przez domyślną wartość lub konstruktorconst- compile-time constantvolatile- nie przestawiaj współbieżnych readów i write’ówstatic- pole statyczne, nieprzypisane do żadnej instancjiunsafe- that’s forbidden knowledge
Kompilator widząc pole lub zmienną const zamienia każde jej wystąpienie w generowanym IL-u na podaną wartość, stąd ograniczenie na compile-time constant.
Niestatyczne pola powinny być prywatne. Jak nie są prywatne, to pewnie coś poszło nie tak przy projektowaniu klasy.
Popularną konwencją nazewnictwa (i zalecaną przez MSDN) jest pisanie prywatnych pól _camelCasem (zaczynanym od podłogi), aczkolwiek spotyka się też zwykły camelCase. Stałe piszemy UpperCamelCasem.
2.9 Properties
Skoro pola są prywatne, to potrzebujemy getterów i setterów. W Javie piszemy własne getValue() setValue(T), C# na szczęście jest lepszy, bo ma properties.
private int _timesSqueaked = 0;
public int TimesSqueaked
{
get
{
return _timesSqueaked;
}
set
{
_timesSqueaked = value;
}
}
Oczywiście tyle linii kodu to sroga przesada, ale da się to zbić używając expression bodies (o tym więcej trochę później)
private int _timesSqueaked = 0;
public int TimesSqueaked
{
get => _timesSqueaked;
set => _timesSqueaked = value;
}
Twórcy C# zauważyli, że po pierwsze, najczęściej nazwy property będą takie same jak ich odpowiadających pól (tylko wielką literą), a po drugie najczęściej getter i setter jest domyślny, get zwraca, set przypisuje. Dlatego da się napisać też tak:
public int TimesSqueaked { get; set; }
Oraz dodać domyślną wartość:
public int TimesSqueaked { get; set; } = 0;
Ta linijka jest równoważna tym wyżej, także na poziomie IL. Możemy nawet nadać różne access specifiery:
public int TimesSqueaked { get; private set; } = 0;
Domyślnie jest taki sam jak samej property. Odwoływanie się do property jest bardzo proste:
var duck = new Duck();
duck.TimesSqueaked = 42; // Calls the set method.
Console.WriteLine(duck.TimesSqueaked); // Calls the get method.
> 42
Jeśli property ma tylko getter i jest on jednolinijkowy, można zastosować nawet bardziej zwięzłą notację:
public int Sum { get; }
public int Number { get; }
public int AverageValue => Sum / Number;
2.10 Metody
Jakie metody są, każdy widzi. Deklarujemy typ zwracany i przyjmowane argumenty. Do instancji, na której wywołano metodę, możemy się odwołać za pomocą this.
public class Duck
{
public void Squeak(string message)
{
Console.WriteLine("Squeak! " + message);
this.TimesSqueaked++; // This `this` is actually redundant.
}
}
Metody mogą mieć zmienną liczbę argumentów dzięki keywordowi params.
public class Duck
{
public int TimesSqueaked { get; private set; }
public void Squeak(params string[] messages)
{
foreach(var message in messages)
{
Console.WriteLine("Squeak! " + message);
++TimesSqueaked;
}
}
}
var duck = new Duck();
duck.Squeak("One.", "Two.", "Three.", "Four!");
> Squeak! One.
> Squeak! Two.
> Squeak! Three.
> Squeak! Four!
Getter i setter property to pełnoprawne metody i mogą zawierać dowolną logikę. Konwencjonalnie jednak nie powinny być bardzo zasobożerne.
Metody mogą też mieć parametry domyślne (ale muszą być compile-time const).
public class Duck
{
public void Squeak(string message = "")
{
Console.WriteLine("Squeak! " + message);
this.TimesSqueaked++; // This this is actually redundant.
}
}
var duck = new Duck();
duck.Squeak();
> Squeak!
2.11 Interfejsy
Interfejsy mogą zawierać tylko i wyłącznie deklaracje publicznych metod (będzie to nieprawda w C# 8, ale to bardziej skomplikowany temat). Gettery i settery to metody:
public interface IDuck
{
void Squeak();
int TimesSqueaked { get; }
}
Klasa może implementować dowolnie wiele interfejsów. Aby implementować interfejs należy dostarczyć publiczne metody o podanych sygnaturach.
2.12 Dziedziczenie
Klasy mogą dziedziczyć po maksymalnie jednej innej klasie i implementować dowolnie wiele interfejsów. Klasy dziedziczą wszystkie metody, pola etc., nie dziedziczą jedynie ctorów (i dtorów).
Każda klasa dziedziczy domyślnie po System.Object.
public class Duck
{
public void Squeak()
{
Console.WriteLine("Squeak!");
}
}
public class BetterDuck : Duck
{
}
BetterDuck duck = new BetterDuck();
duck.Squeak();
> Squeak!
2.13 Przeciążanie
Metody można przeciążać, t.j. deklarować dwie metody o tej samej nazwie, ale z innymi parametrami i/lub z innym typem zwracanym. Kompilator wybierze najlepiej pasującą metodę at compile time.
public void SqueakADuck(Duck duck)
{
Console.WriteLine("Squeak!");
}
public void SqueakADuck(BetterDuck duck)
{
Console.WriteLine("Better squeak!");
}
Duck duck = new Duck();
BetterDuck betterDuck = new BetterDuck();
Duck betterDuckDisguisedAsANormalDuck = new BetterDuck();
SqueakADuck(duck);
SqueakADuck(betterDuck);
SqueakADuck(betterDuckDisguisedAsANormalDuck);
> Squeak!
> Better squeak!
> Squeak!
2.14 Przeładowywanie (overriding)
Metody można przeładowywać (override’ować), ale tylko jeśli w klasie bazowej były zadeklarowane jako virtual. Trzeba to zaznaczyć za pomocą override. Oczywiście mamy polimorfizm.
public class Duck
{
public virtual void Squeak()
{
Console.WriteLine("Squeak!");
}
}
public class BetterDuck : Duck
{
public override void Squeak()
{
Console.WriteLine("Better squeak!");
}
}
Duck duck = new Duck();
BetterDuck betterDuck = new BetterDuck();
Duck betterDuckDisguisedAsANormalDuck = new BetterDuck();
duck.Squeak();
betterDuck.Squeak();
betterDuckDisguisedAsANormalDuck.Squeak();
> Squeak!
> Better squeak!
> Better squeak!
Może się zdarzyć, że chcemy wywołać implementację z klasy bazowej. Służy do tego keyword base.
public class BetterDuck : Duck
{
public override void Squeak()
{
Console.WriteLine("Better squeak!");
base.Squeak();
}
}
var betterDuck = new BetterDuck();
betterDuck.Squeak();
> Better squeak!
> Squeak!
2.15 Hiding
Metodę z klasy wyżej można ukryć, ale rezygnujemy wtedy z polimorfizmu.
public class Duck
{
public virtual void Squeak()
{
Console.WriteLine("Squeak!");
}
}
public class BetterDuck : Duck
{
public new void Squeak()
{
Console.WriteLine("Better squeak!");
}
}
var betterDuck = new BetterDuck();
Duck words = new BetterDuck);
betterDuck.Squeak();
duck.Squeak("Jacuś"), new Duck("Jacuś"),
new Duck("Jacuś"),
new Duck("Jacuś"),
new Duck("Jacuś"),
new Duck("Jacuś"),
new Duck("Jacuś"),
);
> Better squeak!
> Squeak!
2.16 Konstruktory
W skrócie ctor, służy do tworzenia obiektów klasy za pomocą new.
public class Duck
{
public string Name { get; }
public Duck(string name)
{
Name = name;
}
}
var duck = new Duck("Jacuś");
Console.WriteLine(duck.Name);
> Jacuś
Jeśli nie podamy żadnego, C# stworzy dla nas domyślny:
public Duck() : base()
{
}
Konstruktor podklasy musi wywołać jakiś konstruktor klasy bazowej, domyślnie bezparametrowy.
Możemy też wywołać konstruktor z konstruktora za pomocą this.
public class Duck()
{
public Color Color { get; }
public Duck() : this(color)
{
}
public Duck(Color color)
{
Color = color;
}
}
Jeśli mamy bezparametrowy ctor i settery, możemy zainicjować obiekt przy konstrukcji.
public class Duck
{
public string Name { get; set; }
public Color Color { get; set; }
}
var duck = new Duck { Name = "Jacuś", Color = Color.Yellow };
2.17 Sealed
Klasy możemy zamknąć na dziedziczenie poprzez keyword sealed. Można też nim zablokować dalsze przeładowywanie metody wirtualnej.
public class Duck
{
public virtual void Squeak()
{
// ...
}
}
public class BetterDuck : Duck
{
public sealed override void Squeak()
{
// ...
}
}
public class BestDuck : BetterDuck
{
public override void Squeak() // Compilation error - squeak is sealed.
{
}
}
2.18 Klasy abstrakcyjne
Klasy abstrakcyjne służą do implementacji części interfejsu i pozostawienia pewnych szczegółów dla implementujących klasy dziedziczące. Mogą posiadać metody bez implementacji. Klasa abstrakcyjna nie może zostać zainstancjonowana, ale może mieć konstruktor.
public abstract class DuckBase
{
public int TimesSqueaked { get; private set; } = 0;
public DuckBase()
{
Console.WriteLine("Duck base created!");
}
public void Squeak()
{
ProcessSqueak();
++TimesSqueaked;
}
protected abstract void ProcessSqueak();
}
public sealed class Duck : DuckBase
{
public Duck() : base()
{
Console.WriteLine("Duck created!");
}
protected override void ProcessSqueak()
{
Console.WriteLine("Squeak!");
}
}
var duck = new Duck();
duck.Squeak();
Console.WriteLine(duck.TimesSqueaked);
> Duck base created!
> Duck created!
> Squeak!
> 1
2.19 Partial
Klasy, interfejsy i structy można zadeklarować jako partial i rozbić ich implementację na kilka plików.
// Duck.cs
public partial class Duck
{
public string Name { get; }
}
// Duck.Squeak.cs
public partial class Duck
{
public void Squeak()
{
// ...
}
}
Taka deklaracja zostaje złączona w całość w czasie kompilacji. Wszystkie access specifiery muszą być zgodne, sealed przechodzi na cały typ, dziedziczenie po klasie przechodzi na cały typ, implementowana jest suma wszystkich interfejsów.
Metody też mogą być partial, wtedy jeden plik podaje jej sygnaturę i opcjonalnie inny plik ją implementuje. Jeśli implementacja nie istnieje, metoda jest ignorowana przez kompilator.
2.20 Reference types vs Value types
W C# istnieje też keyword struct służący do tworzenia nowych typów. W przeciwieństwie do C++ różnica pomiędzy class a struct istnieje i jest znaczna. Klasy reprezentują reference types, structy value types.
- Reference type - instancja tego typu zawiera referencję (wskaźnik) na blok pamięci zawierający dane obiektu; przekazanie takiej instancji np. jako parametr funkcji i zmodyfikowanie w niej czegoś poskutkuje zmianą oryginalnego obiektu
public void SqueakADuck(Duck duck)
{
duck.Squeak();
}
var duck = new Duck("Jacuś");
SqueakADuck(duck);
Console.WriteLine(duck.TimesSqueaked);
> 1
- Value type - obiekty tego typu są zawsze kopiowane przez wartość; wszystkie typy wbudowane poza
objectistringsą Value types
// This struct is intentionally mutable as a bad example.
public struct DuckData
{
public string Name { get; set; }
public Color Color { get; set; }
public DuckData(string name, Color color)
{
Name = name;
Color = color;
}
}
public void ChangeColor(DuckData data, Color color)
{
data.Color = color;
Console.WriteLine("In: " + data.Color);
}
var duckData = new DuckData("Jacuś", Color.Yellow);
ChangeColor(duckData, Color.Red);
Console.WriteLine("Out: " + duckData.Color);
> In: Red
> Out: Yellow
Odwołanie się do value type zawsze, zawsze, ZaWsZe zwraca kopię. Z tego powodu Value types absolutnie zawsze powinny być immutable, bez żadnych wyjątków.
public struct DuckData
{
public string Name { get; }
public Color Color { get; set; }
public DuckData(string name, Color color)
{
Name = name;
Color = color;
}
public void ChangeColor(Color color)
{
this.Color = color;
Console.WriteLine("In: " + this.Color);
}
}
public class Duck
{
public DuckData Data { get; }
public Duck(string name, Color color)
{
Data = new DuckData(name, color);
}
}
var duck = new Duck("Jacuś", Color.Yellow);
duck.Data.ChangeColor(Color.Red);
Console.WriteLine("Out: " + duck.Data.Color);
> In: Red
> Out: Yellow
Ciekawostka przyrodnicza - wszystkie keywordy int, object, string itp. są tak naprawdę jedynie aliasami na typy struct System.Int32, class System.Object, class System.String.
Domyślną wartością reference type jest null, domyślną wartością value type są wyzerowane bity. Value types nie mogą mieć bezparametrowych ctorów (mają domyślny). Value types nie mogą po niczym dziedziczyć (ani nie można dziedziczyć po nich), ale mogą implementować interfejsy.
2.21 Wolność, równość, braterstwo
Istnieje metod static bool Object.ReferenceEquals(object, object), która sprawdza, czy przekazane obiekty są tym samym. Dla value types w oczywisty sposób zawsze zwraca false, bo przy każdym wywołaniu boxuje obiekty do dwóch różnych.
Istnieje metoda bool Object.Equals(object), którą dziedziczą wszystkie typy. Domyślnie porównanie za pomocą Equals jest równoważne ReferenceEquals dla reference types, a dla value types porównuje każdy bit. Da się ją przeciążyć.
Domyślnie porównanie za pomocą operatora == jest równoważna ReferenceEquals dla reference types i jest niezdefiniowany dla value types. Da się go przeciążyć.
Wszystkie wbudowane value types mają przeciążone == na równoważne Equals. Wyjątkowo string również przeciąża == i porównuje wartości!
Dla wydajności, przy przeciążaniu Equals powinno się przeciążać też long Object.GetHashCode() i sprawdzać najpierw go. Poniżej idiomatyczna implementacja Equals.
public struct DuckData
{
public string Name { get; }
public Color Color { get; }
public DuckData(string name, Color color)
{
Name = name;
Color = color;
}
public override long GetHashCode()
{
var hash = 17;
unchecked
{
hash = (hash * 23) ^ (Name != null ? Name.GetHashCode() : 0);
hash = (hash * 23) ^ (Color != null ? Name.GetHashCode() : 0);
}
return hash;
}
public override bool Equals(DuckData other) =>
GetHashCode() == other.GetHashCode() &&
Name == other.Name &&
Color == other.Color
public override bool Equals(object obj)
{
if(obj is null)
{
return false;
}
if(obj == this)
{
return true;
}
if(GetType() != obj.GetType())
{
return false;
}
return Equals((DuckData)obj);
}
}
2.22 Rzutowanie
- Casty, przy których nie ma ryzyka utraty informacji są implicit.
int a = 42;
long b = a; // Implicit cast.
- Cast może być explicit at compile time, wtedy zawsze się udaje albo nie kompiluje.
var betterDuck = new BetterDuck();
var duck = (Duck)betterDuck;
- Cast może być explicit at runtime, wtedy może rzucić
InvalidCastException.
var duck = new Duck();
var betterDuck = (BetterDuck)duck; // Throws at runtime.
Duck duck = new BetterDuck();
var betterDuck = (BetterDuck)duck; // Succeeds at runtime.
- Cast może być safe at runtime z użyciem
aslubis.
var duck = new Duck();
var betterDuck = duck as BetterDuck; // Fails, betterDuck == null.
Duck duck = new BetterDuck();
var betterDuck = duck as BetterDuck; // Succeeds, duck == betterDuck.
Duck duck = new BetterDuck();
if(duck is BetterDuck)
{
Console.WriteLine("Success!");
}
> Success!
Duck duck = new BetterDuck();
if(duck is BetterDuck betterDuck)
{
betterDuck.Squeak();
}
> Better squeak!
Duck duck = new BetterDuck();
BetterDuck betterDuck = duck as BetterDuck;
if(betterDuck != null)
{
betterDuck.Squeak();
}
> Better squeak!
2.23 Boxing
Przy takim przypisaniu:
int i = 42;
object obj = i;
następuje boxing, czyli opakowanie value type w reference type. Operacja odwrotna to unboxing:
int j = (int)obj;
Boxing zżera czas (dokładniej to a lot of boxing = a lot of garbage collection, which is expensive), więc należy go unikać, jeśli to możliwe.
2.24 Parametry ref i out
C# pozwala na mało eleganckie przekazywanie zmiennych przez referencję. Można więc przekazać referencję na referencję lub referencję na value type.
public void Nullify(ref Duck duck)
{
duck = null;
}
public void Zero(ref int i)
{
i = 0;
}
public void Set(out int i)
{
i = 42;
}
var duck = new Duck("Jacuś");
var i = 42;
Nullify(ref duck);
Console.WriteLine(duck == null ? "Null" : "Not null");
Zero(ref i);
Console.WriteLine(i);
int j;
Set(out j);
Console.WriteLine(j);
> Null
> 0
> 42
Różnica między ref a out - ref musi być przypisany przed przekazaniem, out nie. Metoda musi przypisać coś do out, do ref nie.
2.25 Parse i TryParse
Do konwersji stringów na liczby używa się funkcji Parse lub TryParse. Ta pierwsza rzuca wyjątek przy niepowodzeniu, ta druga zwraca boola i wypełnia out parameter jeśli się udało.
var i = int.Parse("42");
int j;
var success = int.TryParse("42", out j);
Console.WriteLine(success);
Console.WriteLine(j);
> True
> 42
Można też olać out parameter (nie tylko w TryParse, tak ogólnie) i dostać tylko boola.
var success = int.TryParse("42", out _);
Console.WriteLine(success);
> 42
bool TryX(out T t) jest dość częstym patternem w C#.
2.26 Convert
Zaawansowane konwersje pomiędzy bazowymi typami powinny używać Convert.
var d = 1.6;
var i = Convert.ToInt32(d);
Console.WriteLine(i);
> 2
2.27 To be, or not to be?
C# ma rozbudowany mechanizm refleksji, który pozwala np. dostać metadane o typie danego obiektu at runtime.
var duck = new Duck();
Type t = duck.GetType();
Jeśli chcemy dostać informacje o typie statycznym at compile time, najlepiej użyć typeof.
Type t = typeof(Duck);
Można też np. złapać wszystkie metody dostępne dla danego typu, wszystkie interfejsy, klasy bazowe czy wyzerować wszystkie prywatne pola. Use responsibly (which means don’t use at all unless you need it).
Jest też wolna.
2.28 Generics
Suck it, Java.
Generyczne mogą być zarówno typy jak i metody. Przykładem generycznej klasy jest np. List<T>, który może przechowywać dowolne obiekty. W przeciwieństwie do pewnego języka na J, informacja o typie zostaje zachowana at runtime.
public static void PrintDuckType<TDuck>(TDuck duck)
{
var typeName = typeof(TDuck).ToString();
Console.WriteLine("I was passed " + typeName + ".");
}
var duck = new Duck();
var betterDuck = new BetterDuck();
Duck betterDuckDisguisedAsADuck = new BetterDuck();
PrintDuckType(duck);
PrintDuckType(betterDuck);
PrintDuckType(betterDuckDisguisedAsADuck);
> I was passed Duck.
> I was passed BetterDuck.
> I was passed Duck.
public class A { }
public class B<T> : A { }
public class C : B<int> { }
public class D<T, U> : B<T>
Generyki z C# są stricte lepsze niż te z Javy, ale nie są Turing complete jak te z C++. Prawdopodobnie największym ograniczeniem jest brak variadic generics, przez co System/Tuple.cs wygląda jakoś tak:
public class Tuple<T1>
{
T1 Item1 { get; }
/* ... */
}
public class Tuple<T1, T2>
{
T1 Item1 { get; }
T2 Item2 { get; }
/* ... */
}
public class Tuple<T1, T2, T3>
{
T1 Item1 { get; }
T2 Item2 { get; }
T3 Item3 { get; }
/* ... */
}
/* ... */
public class Tuple<T1, T2, T3, T4, T5, T6, T7, TRest>
{
T1 Item1 { get; }
T2 Item2 { get; }
T3 Item3 { get; }
T4 Item4 { get; }
T5 Item5 { get; }
T6 Item6 { get; }
T7 Item7 { get; }
TRest Rest { get; }
/* ... */
}
2.29 Generic constraints
Umożliwianie przekazania dowolnego typu do generycznej klasy lub metody z reguły jest mało przydatne. Można jednak nałożyć ograniczenia na typ generyczny - kazać mu implementować jakieś interfejsy lub dziedziczyć po konkretnej klasie.
public interface IDuck
{
void Squeak();
}
public interface ISqueakTracker
{
int TimesSqueaked { get; }
}
public class Duck : IDuck, ISqueakTracker
{
public int TimesSqueaked { get; protected set; } = 0;
public virtual void Squeak()
{
Console.WriteLine("Squeak!");
++TimesSqueaked;
}
}
public static void SqueakIfNew<TDuck>(TDuck duck)
where TDuck : IDuck, ISqueakTracker
{
if(duck.TimesSqueaked > 0) // ISqueakTracker
{
Console.WriteLine("No squeaking for you!");
return;
}
duck.Squeak(); // IDuck
}
SqueakIfNew(duck);
SqueakIfNew(duck);
> Squeak!
> No squeaking for you!
Istnieją też inne, specjalne ograniczenia:
where T : class-Tmusi być typem referencyjnym;where T : struct-Tmusi być value typem;where T : new()-Tmusi mieć dostępny, bezparametrowy ctor
Jeśli nadajemy ograniczenia na dwa typy to piszemy drugie where.
public class A<T, U> where T : class, new()
where U : T
{
}
Słyszałem, że w jakimś głupim języku jest takie dziwne ograniczenie, że nie można zrobić tablicy typu generycznego.
public static void LaughsInCSharp<TeeHeeHee>()
{
var arr = new TeeHeeHee[42];
}
Dodatkowo, jeśli się nie mylę, to stworzenie generyka od typu int jest niemożliwe w Javie i trzeba robić boxing. Oczywiście C# nie jest tak skrajnie upośledzony i parametrem generycznym może być dowolny typ. Nie jest jednak tak fajny jak C++ i nie pozwala, żeby to była np. stała.
2.30 Nullable<T>
Value types nie mogą być nullem, ale czasem może być to potrzebne. Z tego powodu istnieje wrapper class Nullable<T>, który można też wywołać lukrem syntaktycznym T?.
public class Nullable<T> where T : struct
{
private bool hasValue;
internal T value;
/* ... */
}
Nullable<int> i = 3;
i = null;
To to samo co
int? i = 3;
i = null;
Nullable<T> boxuje!
2.31 Kolekcje
.NET udostępnia generyczne kolekcje i interfejsy w System.Collections.Generic.
Intefejsy:
IEnumerable<T>- cokolwiek, po czym można się przeiterować, korzysta z tegoforeach;ICollection<T>- dziedziczy poIEnumerable<T>, udostępnia operacjeAdd(T),Remove(T),Contains(T)i propertyCount;IList<T>- dziedziczy poICollection<T>, udostępnia indeksator[];IDictionary<TKey, TValue>- dziedziczy poICollection<KeyValuePair<TKey, TValue>>, udostępnia dodawanie par klucz-wartość i odwoływanie się po kluczu przez indeksator.
Klasy:
List<T>- implementujeIList<T>, rozszerzalna tablica tak jakstd::vector<T>z C++;Dictionary<TKey, TValue>- implementujeIDictionary<TKey, TValue>, hashmapa;Stack<T>- stos;Queue<T>- kolejka FIFO;LinkedList<T>- lista dwukierunkowa;HashSet<T>- zgaduj-zgadula;SortedDictionary<TKey, TValue,SortedSet<T>- odpowiednikiDictionaryiHashSetna drzewach BST;SortedList<TKey, TValue>- posortowana lista (taka ze wstawianiem w )Lookup<TKey, TValue>- słownik, ale do każdego klucza może być wiele wartości
Lista jest najpowszechniejszą z kolekcji. Do iterowania się po kolekcjach w przypadków używamy foreacha. Do inicjalizowania kolekcji wygodnie użyć… no cóż, inicjalizatora kolekcji.
var list = new List<int> { 2, 1, 3, 7 };
foreach(var num in list)
{
Console.Write(num);
}
Console.WriteLine();
> 2137
2.32 Ko- i kontrawariancja
Intuicja:
- Kowariancja jest wtedy, kiedy nic nie wkładamy, ale wyciągamy.
- Kontrawariancja jest wtedy, kiedy wkładamy, ale nie wyciągamy.
Nie zawsze żeby wyjąć trzeba włożyć.
IEnumerable<Duck> = new List<BetterDuck>();
Nasze interfejsy mogą być ko- lub kontrawariantne dzięki keywordom out i in.
public interface IDuckGenerator<out TDuck> where TDuck : Duck
{
TDuck Generate();
}
public interface IDuckSqueaker<in TDuck> where TDuck : IDuck
{
void Squeak(TDuck);
}
/* DuckGenerator and DuckSqueaker implementations... */
// Covariance.
IDuckGenerator<Duck> duckGenerator = new DuckGenerator<BetterDuck>();
// Contravariance.
IDuckSqueaker<BetterDuck> duckSqueaker = new DuckSqueaker<Duck>();
2.33 Stringi
Wspomnieliśmy już, że porównywanie zmiennych typu string za pomocą == jest intuicyjne. Należy pamiętać także o bardzo ważnej rzeczy - stringi są immutable. To znaczy, że wywołanie:
var str = "Hello";
str += " World!";
spowoduje stworzenie zupełnie nowego stringa "Hello World!" i przypisanie go do zmiennej str. Więc gdyby chcieć np. stworzyć z ciągu zer i jedynek napis składający się z liter a i b w taki sposób:
string ToABString(int[] sequence)
{
var result = "";
foreach(var element in sequence)
{
result += (element == 0 ? "a" : "b");
}
return result;
}
to złożoność czasowa i pamięciowa wyniesie sequence.Length. Do takich operacji służy klasa StringBuilder (.NET Standard).
string ToABString(int[] sequence)
{
var stringBuilder = new StringBuilder();
foreach(var element in sequence)
{
stringBuilder.Append(element == 0 ? 'a' : 'b');
}
return stringBuilder.Build();
}
Stringi też występują w różnych smakach. Mamy zwykłe, interpolowane i verbatim.
- Interpolated string - pozwala na wplecenie wartości zmiennych do literału
public class Duck
{
public string Name { get; }
public int TimesSqueaked { get; } = 0;
public Duck(string name)
{
Name = name;
}
public void Squeak()
{
++TimesSqueaked;
Console.WriteLine($"Duck {Name}: Squeak! [Squeak #{TimesSqueaked}]");
}
}
Jest to “mniej więcej równoważne” napisaniu
Console.WriteLine("Duck " + Name + ": Squeak! [Squeak #" + TimesSqueaked + "]");
A dla ścisłości jest dokładnie równoważne
string.Format("Duck {0}: Squeak! [Squeak #{1}]", Name, TimesSqueaked);
- Verbatim string - pozwala na dosłowne interpretowanie stringa
var str = "\n";
var verbatimStr = @"\n";
Console.WriteLine(str);
Console.WriteLine(verbatimStr);
>
>
> \n
Można te typy łączyć ze sobą
var duck = new Duck("Jacuś");
var mix = $@"{duck.Name}\n";
Console.WriteLine(mix);
> Jacuś\n
2.34 Więcej o verbatim
Jak już przy tym jesteśmy, znaczka @ można użyć też do escape’owania keywordów.
// object object = new object() // Does not compile.
object @object = new object(); // This is correct.
2.35 Statyczne klasy
Czasami metody albo stałe nie należą do żadnej konkretnej instancji, ale są ogólną własnością klasy. Deklarujemy je wtedy jako static. Często jednak zdarza się, że mamy wiele pomocniczych metod, które nijak nie są związane z konkretnym obiektem (np. klasa Math). Wtedy taką klasę można zadeklarować jako statyczną. Nie może mieć ona ctora i nie da się stworzyć jej instancji. Wszystkie jej składowe też muszą być statyczne.
public static class Math
{
public const double E = 2.7182818284590452354;
public const double PI = 3.14159265358979323846;
public static int Max(int val1, int val2) => (val1 >= val2) ? val1 : val2;
}
2.36 Extension methods
Bardzo ciekawym mechanizmem jak na statycznie typowany język są extension methods. Jest to co prawda jedynie lukier syntaktyczny, ale pozwala nam wywoływać metody na obiektach danego typu jakby były ich memberami.
public static class DuckExtensions
{
public static void SqueakNTimes(this Duck duck, int n)
{
for(var i = 0; i < n; ++i)
{
duck.Squeak();
}
}
}
var duck = new Duck();
duck.SqueakNTimes(3);
> Squeak!
> Squeak!
> Squeak!
Nie można jednak w ten sposób obejść access specifierów - widzimy tylko publiczne rzeczy (ewentualnie internal).
2.37 Operatory
W C# mamy standardowe operatory jak w C lub C++. Przydatną informacją jest to, że operatory || oraz && są leniwe (defacto są zaimplementowane za pomocą | i &). W przypadku bool? zachowanie tych operatorów jest takie jak w SQL-u (stety/niestety).
C# ma też tzw. null-coalescing operator `??
a ?? b;
jest równoważne
a != null ? a : b;
Oraz operator ?.
a?.Property;
jest równoważne
a != null ? a.Property : null;
2.38 Przeciążanie operatorów
Tak, można! Nie można tylko przypisania i ||/&& (ale można |/&). Można nawet przeciążyć ==, choć jest to niezalecane. Porównania muszą być przeciążane parami.
public class Duck
{
public string Name { get; }\
public Duck(string name)
{
Name = name;
}
public static bool operator ==(Duck duck1, Duck duck2) => duck1?.Name == duck2?.name;
public static bool operator !=(Duck duck1, Duck duck2) => !(duck1 == duck2);
}
var duck = new Duck("Jacuś");
var otherDuck = new Duck("Jacuś");
Console.WriteLine(duck == otherDuck);
> True
2.39 Indekser
Nasz typ może definiować swój indekser, tj. zachowanie dla operatora [].
public class MyTableWrapper<T>
{
private readonly T[] _tab;
public MyTableWrapper(int length)
{
_tab = new T[length];
}
public T this[int i]
{
get => _tab[i];
set => _tab[i] = value;
}
}
2.40 Custom cast
Można zdefiniować swoje własne jawne i niejawne castowanie za pomocą implicit i explicit.
public class A
{
public static implicit operator B(A a)
{
/* ... */
}
}
public class B
{
public static explicit operator A(B b)
{
/* ... */
}
}
A a = new A();
B b = new B();
A bAsA = (A)b;
B aAsB = a;
2.41 Tuples (ValueTuple)
Wspomnieliśmy wcześniej o Tuple’ach, jednak w C# 7 używa się ValueTuples. Pozwalają one na nazwanie pól:
var myPoint = (x: 4, y: 2);
Console.WriteLine(myPoint.x);
Console.WriteLine(myPoint.y);
> 4
> 2
Takie tuple można też dekonstruować w miejscu:
var (x, y) = myPoint;
Console.WriteLine(x);
Console.WriteLine(y);
> 4
> 2
ValueTuple to struct.
2.42 Wyjątki
Wyjątki rzuca się throw, każdy wyjątek musi dziedziczyć po System.Exception. Wyjątki łapie się konstrukcją try/catch i można je zrethrowować.
try
{
/* ... */
}
catch(InvalidOperationException exception)
{
Console.WriteLine(exception.Message);
throw;
}
Jeśli nie obchodzi nas jaki wyjątek łapiemy (rzadko), piszemy:
try
{
/* ... */
}
catch
{
/* ... */
}
jeśli nie potrzebujemy obiektu wyjątku, możemy napisać
try
{
/* ... */
}
catch(InvalidOperationException) // Without declaring a variable.
{
/* ... */
}
C# ma też konstrukcję finally. Kod w bloku finally wywołuje się zawsze, nawet w przypadku wyjątku. Może wystąpić bez catcha. Ta konstrukcja mogłaby się przydawać np. do wywoływania Dispose, gdyby nie using.
2.43 Garbage collector
Nie będziemy wchodzić w szczegóły GC. Najważniejsze informacje to:
- Wszystkie obiekty na stercie, do których nie istnieje ścieżka w grafie obiektów są niekatywne.
- GC od czasu do czasu przechodzi się po stercie i usuwa nieaktywne obiekty. Cały proces jest skomplikowany i bierze w nim udział wiele enzymów. Sterta jest defragmentowana, obiekty są podzielone na 3 generacje, yada yada.
- Value types są zazwyczaj alokowane na stosie. Wyjątki to między innymi pola klas i rzeczy złapane przez delegaty.
W związku z tym, że obiekty mogą trochę poczekać zanim zostaną zniszczone, nawet jak już są niepotrzebne, powstał Dispose pattern.
2.44 Dispose
Jeśli klasa trzyma jakiś managed resource, który jest “ciężki”, np. file handle, połączenie z bazą danych itp., powinien implementować IDisposable. Interfejs ten zawiera jedną metodę void Dispose(), która ma zwolnić zasoby. Kanoniczna implementacja dispose pattern bez finalize wygląda tak:
public class Repository : IDisposable
{
private bool _disposed = false;
private DbConnection _connection; // Managed, disposable resource.
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
public protected virtual void Dispose(bool disposing)
{
if(_disposed)
{
return;
}
if(disposing)
{
_connection.Dispose();
}
_disposed = true;
}
}
Skomplikowanie tej implementacji wynika z tego, że klasy dziedziczące po naszej mogą mieć własne disposabale resources i do tego finalizery (o których za chwilę). Ergo, jeśli nasza klasa jest sealed to wystarczy coś takiego:
public void Dispose()
{
_connection.Dispose();
}
Święta zasada C# na temat IDisposable to:
Na każdym obiekcie implementującym IDisposable należy wywołać metodę Dispose DOKŁADNIE RAZ.
Jest jeszcze dość naturalna zasada, iż obiektów, które już zdisposowaliśmy nie można używać do niczego. Każdy call na obiekcie, który już był disposed ma święte prawo strzelić nam w twarz wyjątkiem (jest nawet specjalny wyjątek na takie okoliczności, ObjectDisposedException).
Wspomnieliśmy wcześniej o bloku finally. Jest jednak o wiele przyjemniejszy syntax sugar w postaci dyrektywy using.
public static void DoStuffWithRepo()
{
using(var repo = new Repository())
{
repo.DoStuff();
}
}
jest równoważne
public static void DoStuffWithRepo()
{
var repo = new Repository()
try
{
repo.DoStuff();
}
finally
{
repo?.Dispose();
}
}
Można tę dyrektywę stackować:
public static void DoStuffWithRepo()
{
using(var repo = new Repository())
using(var someOtherDisposable = new SomeOther())
using(var moreDisposables = new SomeOther())
{
repo.DoStuff();
/* ... */
}
}
2.45 Finalize
Finalize/destruktor służy do zwalniania unmanaged resources. Takie zasoby też powinny być zwalniane przez Dispose, ale finalizer służy jako safeguard, gdyby wywołanie Dispose zawiodło albo jakiś JavaScript-Ninja o nim zapomniał. Zawsze implementujemy Dispose pattern, a potem dodajemy:
~MyClass
{
Dispose(false);
}
Jako początkujący programista C# powinno się zaakceptowac istnienie finalizerów i nigdy nie próbować ich używać.
Po pierwsze - jeśli kiedykolwiek trzeba pracować z unmanaged resources to i tak będzie trzeba przeczytać MSDN-a jeszcze raz i mieć pewność, że się wie co się robi.
Po drugie - Finalize should be a last resort, specialize SafeHandle instead.
2.46 Atrybuty
Atrybuty zawierają metadane. Same z siebie nie za wiele robią, ale można się do nich dostać przez refleksję i wyłuskać dane (będziemy ich bardzo używać przy ASP i EF). Każdy atrybut ma nazwę kończącą się na Attribute i dziedziczy po Attribute.
Przykładowo atrybut ObsoleteAttribute, używany przez kompilator do nakrzyczenia na użytkownika danej metody:
public class MyClass
{
[Obsolete]
public void MyMethod()
{
/* ... */
}
}
Jeśli konstruktor atrybutu przyjmuje jakieś argumenty, to podajemy je w tagu.
public class MyClass
{
[Obsolete("This method is deprecated because of reasons, don't use it")]
public void MyMethod()
{
/* ... */
}
}
Przy tworzeniu własnych atrybutów trzeba podać przy deklaracji do jakich pól będzie stosowany.
[AttributeUsage(AttributeTargets.Class | AttributeTargets.Struct)]
public class MyAttribute : Attribute
{
/* ... */
}
2.47 nameof
Taki mały feature, nameof zostaje statycznie zamienione na nazwę zmiennej/pola/metody etc.
var duck = new Duck();
Console.WriteLine($"{nameof(duck.Squeak)}!");
> Squeak!
2.48 Delegates
Delegaty to type-safe function references. Najpierw trzeba zadeklarować sam typ:
public delegate int BinaryOperator(int lhs, int rhs);
Może on być składową jakiejś klasy albo być luzem w namespace’ie. Następnie możemy przypisać do zmiennej tego typu jakąś metodę i ją wywołać.
public static int Plus(int a, int b) => a + b;
BinaryOperator binaryOperator = Plus;
Console.WriteLine(binaryOperator(17, 25));
> 42
Delegaty są w rzeczywistości jeszcze potężniejsze, można do jednej takiej zmiennej przypisać wiele metod, które zostaną wykonane kolejno z tymi samymi argumentami. Delegat zwróci wartość z ostatniej wywołanej metody.
public static int Plus(int a, int b)
{
Console.WriteLine($"{a} + {b} = {a + b}");
return a + b;
}
public static int Minus(int a, int b)
{
Console.WriteLine($"{a} - {b} = {a - b}");
return a - b;
}
BinaryOperator binaryOperators = Plus;
binaryOperators += Minus;
Console.WriteLine(binaryOperators(17, 25));
> 17 + 25 = 42
> 17 - 25 = -8
> -8
Po metodach zawartych w delagacie można się przeiterować:
BinaryOperator binaryOperators = Plus;
binaryOperators += Minus;
foreach(BinaryOperator func in binaryOperators.GetInvocationList())
{
Console.WriteLine(func(17, 25));
}
> 17 + 25 = 42
> 42
> 17 - 25 = -8
> -8
.NET udostępnia dwa fundamentalne, generyczne typy delagatów:
Action<T1, T2, ..., TN>- metoda niezwracająca żadnej wartości, przyjmująca N argumentów typów kolejnoT1,T2, …,TN;Func<T1, T2, ..., TN, TResult>- metoda zwracającaTResulti przyjmująca N argumentów typów kolejnoT1,T2, …,TN;
Jeśli przypiszemy do delegata instance method, to delegat złapie tę konkretną instancję i this w ciele przypisanej metody będzie się do niej odwoływać.
Typy delegatów są kowariantne ze względu na typ zwracany i kontrawariantne ze względu na typy przyjmowane.
public static Derived Foo(Base b1, Base b2)
{
return new Derived();
}
Func<Derived, Derived, Base> func1 = Foo; // Legal assignment.
Uwaga: Typy delegatów są ze sobą zupełnie niezgodne (poza wspomnianą ko- / kontrawariancją). Np. takie przypisanie:
BinaryOperator binaryOperator = Plus;
Func<int, int, int> f = binaryOperator;
jest nielegalne. Z tego też powodu nie można używać var przy deklaracjach obiektów delegatów.
2.49 Lambdy
Bardzo często do delegatów przypisujemy krótkie wyrażenia i nie ma sensu tworzyć dla nich dedykowanych metod. I tu wchodzą lambdy, całe na biało.
BinaryOperator binaryOperator = (int a, int b) => a + b;
Typy po prawej mogą zostać wydedukowane przez kompilator.
BinaryOperator binaryOperator = (a, b) => a + b;
Jakie ograniczenia mają lambdy względem zwykłych metod? Praktycznie żadnych, poza małą rzeczą związaną z dynamic. Mogą mieć pełnoprawne ciała:
BinaryOperator binaryOperator = (a, b)
{
Console.WriteLine("Lambdas are awesome!");
return a + b;
};
Console.WriteLine(binaryOperator(17, 25));
> Lambdas are awesome!
> 42
Argumenty lambd mogą być ref i out.
Lambdy mogą nie mieć argumentów
Func<int> f = () => 42;
mogą nic nie zwracać
Action<int> f = x => Console.WriteLine(x);
mogą nic nie przyjmować i nic nie zwracać
Action f = () => Console.WriteLine(42);
No i lambdy są kompatybilne z dowolnym delegatem o odpowiedniej sygnaturze.
BinaryOperator bin = (a, b) => a + b;
Func<int, int, int> fun = (a, b) => a + b;
2.50 Lazy<T>
Wspomnieliśmy, że konwencjonalnie properties powinny nie być resource-intensive. Czasami jednak chcemy mieć propertę, której inicjalizacja zajmuje dużo czasu, bo np. reprezentuje bardzo duży obiekt. W takim wypadku możemy użyć klasy Lazy<T>. Przyjmuje ona inicjalizator i wykonuje go przy pierwszym odwołaniu do property Value. Każde kolejne odwołanie spowoduje zwrócenie raz utworzonego obiektu. Implementuje to schemat lazy initialization - obiekt jest tworzony dopiero wtedy, kiedy jest potrzebny, ale tylko raz.
public class GiantDuck
{
public string Name { get; }
/* A lot of members */
}
public class GiantDuckContainer
{
public Lazy<GiantDuck> Duck { get; }
public GiantDuckContainer
{
Duck = new Lazy<GiantDuck>(() => new GiantDuck("Jacuś"));
}
}
Uważny słuchacz powinien się teraz spytać, jak będzie to działać, jeśli kilka wątków odwoła się do Value jednocześnie. Domyślnie działa to sensownie - jest thread safe. Można to explicitly wyłączyć używając innego konstruktora Lazy<T>, który przyjmuje bool isThreadSafe. Powinno się tego używać tylko wtedy, kiedy wydajność jest szczególnie ważna, przy zachowaniu szczególnej ostrożności i włączonym kierunkowskazie.
Jeśli chcemy tworzyć obiekt za pomocą domyślnego konstruktora, to możemy pominąć inicjalizującą lambdę, tzn.
new Lazy<T>(); // Thread safe.
new Lazy<T>(false); // Non-thread safe.
są równoważne
new Lazy<T>(() => new T()); // Thread safe.
new Lazy<T>(() => new T(), false); // Thread safe.
Dodatkowo, jeśli niestandardowa inicjalizacja wyrzuci wyjątek, to każde kolejne odwołanie do tego samego Value wyrzuci ten sam wyjątek.
2.51 Lokalne metody
Czasami chcemy mieć metodę, którą wywołamy kilkukrotnie w czasie wywoływania naszej logiki. Nie chcemy powtarzać kodu, ale nie chcemy też tworzyć pomocniczej metody używanej tylko w jednym miejscu i nie mającej wartości poza tym konkretnym miejscem. Można by utworzyć delegata do tej metody, ale jest to niepotrzebne alokowanie pamięci i wywołanie metody potrwa trochę dłużej. Lepiej użyć lokalnej metody:
public static int CalculateStuff(params (int, int)[] vals)
{
var sum = 0;
int Plus(int a, int b) => a + b;
int Minus(int a, int b) => a - b;
foreach(var (a, b) in vals)
{
sum += Plus(a, b) + Minus(a, b);
}
return sum / vals.Length;
}
Console.WriteLine(CalculateStuff((17, 25), (11, 33), (35, 21)));
> 42
2.52 To już jest (prawie) koniec
Zostało nam programowanie asynchroniczne i LINQ, ale o tym w następnych działach.
3. “Yyy, na MIMie nie uczą o SOLID!!!1”
SOLID principles:
- Single responsibility - każda klasa powinna mieć dokładnie jedną, ściśle zdefiniowaną odpowiedzialność.
- Open-closed - klasy powinny być otwarte na rozszerzanie, ale zamknięte na modyfikacje.
- Liskov substitution principle - święta zasada projektowania hierarchii dziedziczenia - jeśli typ B dziedziczy po A, to B jest A.
- Interface segregation - interfejsy powinny być najmniejsze możliwe, w szczególności użytkownik nie powinien nic wiedzieć o metodach, których nie potrzebuje.
- Dependency inversion - depend on abstractions, not concretions.
No to już uczą. Szczególną uwagę poświęcimy literce D.
3.1 Inversion of Control
Inversion of Control jest sposobem na spełnienie SOLID-owego D. Załóżmy, że nasz kod chce wyciągnąć coś z bazy danych. Ma do tego repozytorium:
public class Duck
{
public string Name { get; set; }
public Color Color { get; set; }
}
public interface IRepository
{
Duck GetDuckByName(string name);
}
public class Repository : IRepository, IDisposable
{
/* ... */
public Repository(string connectionString)
{
/* ... */
}
/* ... */
}
Przykładowy Main wyglądałby jakoś tak:
public class Program
{
private const ConnectionString = "UserID=posgres;Password=postgres;Host=localhost;Port=5432;Database=duck_db";
public static void Main()
{
using(var repository = new Repository(ConnectionString))
{
var duck = repository.GetDuckByName("Jacuś");
Console.WriteLine(duck is null ? "Nie ma Jacusia :(" : "Jest Jacuś! :>");
}
}
}
Mamy tutaj bardzo mocny coupling między Mainem a repozytorium. Jest on wręcz nietestowalny. “New is glue”, and glueing the code is bad.
Tutaj Main ma kontrolę nad tym, jakiego repozytorium używa. Trzeba tę kontrolę odwrócić (IoC) i tę zależność od repozytorium wstrzyknąć (Dependency Injection, DI).
public class Program
{
public static void Main(IRepository repository)
{
var duck = repository.GetDuckByName("Jacuś");
Console.WriteLine(duck is null ? "Nie ma Jacusia :(" : "Jest Jacuś! :>");
}
}
Teraz to wywołujący Maina ma kontrolę nad tym, jakie repozytorium dostanie aplikacja. W szczególności może to ustawić za pomocą statycznych metadanych np. w pliku konfiguracyjnym. Teraz tę metodę można łatwo przetestować, bo możemy podać testowe repozytorium, nad którym mamy pełną kontrolę.
Don’t let your code get the better of you. Take control.
3.2 IoC Container / Service Locator
Powyższy pattern jest bardzo powszechny. Praktycznie każdy element aplikacji ma jakieś zależności i te zależności powinny być decoupled od kodu, który ich używa, połączony jedynie ładnym interfejsem. Do osiągnięcia tego używa się kontenerów IoC. My zajmiemy się Microsoftowym ServiceProviderem dostępnym out-of-the-box w ASP .NET Corze.
Korzystając z poprzedniego przykładu użyjmy IServiceProvidera do ustawienia odpowiedniego repozytorium.
public static class Startup
{
public void ConfigureServices(IServiceCollection services)
{
const string connectionString = "UserID=posgres;Password=postgres;Host=localhost;Port=5432;Database=duck_db";
services.AddScoped<IRepository, Repository>(sp => new Repository(connectionString));
}
}
Nie przejmując się tym, co znaczy Scoped, we’re done. Teraz automatycznie jeśli potrzebowali wstrzykniętego IRepository, ServiceProvider podczas instancjonowania odpowiedniego obiektu, który wymaga IRepository w konstruktorze, stworzy nowe repozytorium i je przekaże (akurat z Mainem to nie zadziała, ale disregard that).
Każda zależność w aplikacji powinna być skonfigurowana w podobny sposób. Później jeszcze do tego wrócimy i powiemy co to Scoped i co robią inne modyfikatory.
3.3 Testowanie (XUnit)
Większość rzeczy związanych z czystym kodem i elegancką architekturą ma dwa cele - po pierwsze, wprowadzenie zmiany powinno wymagać nakładu pracy mniej więcej liniowo proporcjonalnego do rozmiaru tej zmiany. Po drugie, kod musi być testowalny. Nie będziemy tutaj poruszać zagadnień Test Driven Development, ale postaramy się przynajamniej nie robić Yolo Driven Development.
Testowanie jest w swych założeniach banalne - chcemy wziąć interfejs danego elementu i przetestować, czy metody w tym interfejsie robią to, co powinny. Przypatrzymy się bardzo na szybko XUnitowi jako frameworkowi do testów i NSubstitute do mocków.
Założenia unit-testów
Unit testy powinny być:
- Deterministyczne - ten sam kod zawsze przechodzi lub zawsze failuje dany test.
- Niezależne - wykonanie jednego testu nie może w żaden sposób wpłynąć na wykonanie innych
- Zwięzłe - jeśli test jest długi, prawdopodobnie metoda jest zbyt skomplikowana
- Odizolowane - jeden unit test powinien testować jeden unit, wszystkie zależności powinny być zmockowane
Arrange, Act, Assert
Standardowym workflowem do tworzenia unit testów jest AAA - Arrange, Act, Assert. Zobaczmy przykładowy test klasy Calculator.
public class CalculatorUnitTests
{
[Fact]
public void Square_GivenAnyInteger_ReturnsItsSquare()
{
// ARRANGE
const int value = 42;
const int expectedSquare = value * value;
var systemUnderTest = new Calculator();
// ACT
var actualSquare = systemUnderTest.Square(value);
// ASSERT
Assert.Equal(expectedSquare, actualSquare);
}
}
XUnit rozróżnia dwa rodzaje testów - fakty i teorie. Fakty są prawdziwe zawsze, niezależnie od danych testowych, teorie tylko dla niektórych.
Spróbujmy przetestować coś korzystającego z naszego repozytorium i wepchnijmy tam jak najwięcej rzeczy o testowaniu. Załóżmy, że mamy metodę, która zwraca losowo wybraną kaczkę, a nasz serwis przyjmuje kolor i zwraca imię kaczki, jeśli trafiliśmy w kolor, a jeśli nie, to rzuca wyjątek. Pomińmy sensowność takiego serwisu i metody w repo.
public class DuckGuesser
{
private readonly IRepository _repository;
public Duck(IRepository repository)
{
_repository = repository;
}
public string GuessColor(Color color)
{
var duck = _repository.GetRandomDuck();
return duck.Color == color ? duck.Name : throw ApplicationException($"Wrong color, guessed {color}, was {duck.Color}.");
}
}
public class DuckGuesserUnitTests
{
public static TheoryData<Duck> DuckData => new TheoryData<Duck>
{
{
new Duck("Jacuś", Color.Yellow);
},
{
new Duck("Jacuś", Color.Red);
},
{
new Duck("Yellow", Color.Yellow);
},
{
new Duck("Yellow", Color.Green);
}
}
[Theory]
[MemberData(nameof(DuckData))]
public void GuessColor_WhenColorMatchesWithGivenDuck_ReturnsDuckName(Duck duck)
{
// ARRANGE
var expectedName = duck.Name;
var color = duck.Color;
var repository = Substitute.For<IRepository>();
repository.GetRandomDuck().Returns(duck);
var systemUnderTest = new DuckGuesser(repository);
// ACT
var resultName = systemUnderTest.GuessColor(color);
// ASSERT
Assert.Equal(expectedName, resultName);
}
[Theory]
[MemberData(nameof(DuckData))]
public void GuessColor_WhenColorDoesNotMatchWithGivenDuck_ThrowsApplicationException(Duck duck)
{
// ARRANGE
var color = duck.Color == Color.Yellow ? Color.Green : Color.Yellow;
var repository = Substitute.For<IRepository>();
repository.GetRandomDuck().Returns(duck);
var systemUnderTest = new DuckGuesser(repository);
// ACT & ASSERT
Assert.Throws<ApplicationException>(() => systemUnderTest.GuessColor(color));
}
}
Ten test zdecydowanie nie jest najlepszy - co można by w nim poprawić?
4. Jak działa ASP .NET?
Zakładam, że wiemy, jak działa internet, protokół HTTP, że HTML jest statyczny i trzeba niestety używać JS-a itd.
ASP .NET to framework do server-side web-app programming. Potrafi tworzyć ładne strony, generować HTML-a a także da się w nim zrobić wydajne REST API. My będziemy się skupiać na tworzeniu stron.
4.1 Dlaczego asynchroniczne przetwarzanie jest ważne?
Na serwerze, na którym odpalony jest ASP .NET jest pewna pula wątków, tzw. worker threads. W momencie, w którym dostaniemy HTTP request z zewnątrz, jeden z tych wątków się zrywa i zaczyna na niego odpowiadać. Do zrobienia może mieć sporo, musi najpierw zrobić routing, czyli znaleźć metodę, która ma na zapytanie odpowiedzieć; później wysyła zapytania do serwisów, co w przypadku architektury mikroserwisowej łączy się z wysłaniem czegoś po sieci. Na koniec z reguły trzeba dostać się do bazy danych, a to też trochę trwa. No i jak już w końcu zrobimy to co trzeba, to należy z tym wrócić i wysłać odpowiedź.
Przy prostym zapytaniu, podróż do bazy danych zajmie lwią część czasu odpowiedzi na request. Jeśli serwer czeka kilkanaście milisekund na odpowiedź bazy, to prawdopodobnie nic w tym czasie nie robi. Gdyby tylko dało się np. rzucić request do bazy i zająć się czymś innym, w czasie gdy on się przetwarza…
4.2 Task<T> oraz async/await
Wszystkie metody, które
- wysyłają HTTP requesty,
- pytają o coś bazę danych,
- wczytują albo zapisują rzeczy do pliku,
etc. mają swoje odpowiedniki Async (konwencja nazewnicza MethodNameAsync). Takie metody zwracają obiekty typu Task lub Task<T>, które implementują awaitable pattern. Załóżmy, że chcemy wysłać GET request i coś tam zrobić z odpowiedzią.
public static readonly HttpClient client = new HttpClient();
var getTask = client.GetStringAsync("http://www.example.com/recepticle.aspx");
Teraz możemy sobie coś zrobić w międzyczasie. Kiedy będziemy potrzebowali odpowiedzi, robimy await.
var responseString = await getTask;
Awaitable pattern gwarantuje, że wywołanie await zwróci nam coś typu T (albo wystrzeli wyjątkiem). Jeśli to zadanie nie zostało zakończone, to zmienimy control flow - wykonanie wróci do miejsca, w którym wywołana została nasza metoda. Trzeba poinformować o tym kompilator keywordem async i zwrócić Task lub Task<T>.
public async Task SendRequestAsync()
{
var getTask = client.GetStringAsync("http://www.example.com/recepticle.aspx");
SpinRoundAndRoundAndRound();
var responseString = await getTask;
DoStuffWithResponse(responseString);
}
Teraz ktokolwiek, kto wywołał tę metodę, może kręcić się w kółko aż mu się nie znudzi i nie zrobi await na zwróconym przez nas Tasku.
W szczególności, nasz worker thread może stwierdzić, że skoro nie ma nic do roboty podczas gdy pakiety lecą sobie w świat do bazy danych, to zajmie się requestem innego użytkownika. W momencie kiedy innermost Task się zakończy, przybiegnie dokończyć swoją pracę (uwaga: nie musi to być ten sam wątek).
async/await to temat bardzo obszerny i skomplikowany (praktycznie cały C#5 dotyczył jedynie wprowadzenia tegoż patternu), więc powyższy opis należy traktować jako jeszcze bardziej skrótowy i pomijający szczegóły niż w innych miejscach prezentacji. Byłbym w stanie pewnie poprowadzić drugi cały wykład jedynie o asyncu.
4.3 Dygresja: Task.Run
O ile programowanie asynchroniczne bardzo się przydaje przy IO-bound operations, to do CPU-bound operations również mamy bardzo proste i skuteczne mechanizmy. Po pierwsze, możemy odpalić dowolne zadanie i skierować je do puli wątków za pomocą Task.Run.
var task = Task.Run(() => SpinRoundAndRoundAndRound());
SpinRoundAndRoundAndRound();
await task;
Możemy odpalić tak wiele zadań i poczekać aż wszystkie się skończą, w nadziei, że na wielordzeniowym procesorze dostaniemy speedup.
decimal pi;
decimal e;
decimal one;
var tasks = new List<Task>
{
Task.Run(() => pi = CalculatePi()),
Task.Run(() => e = CalculateE()),
Task.Run(() => one = CalculateOne())
};
await Task.WaitAll(tasks);
Uwaga: robienie await jako ostatniej instrukcji w metodzie nie ma absolutnie żadnego sensu. Lepiej zwrócić taki Task.
4.4 Dygresja: Parallel
Mamy też statyczne metody Parallel.For i Parallel.Foreach, które robią to co można się domyślić, że robią. Nie będziemy wnikać w szczegóły.
4.5 Dygresja: PLINQ
Istnieje też współbieżna wersja LINQ, którą można zawołać konwertując IEnumerable za pomocą AsParallel(), ale o LINQ będzie później.
4.6 MVC
ASP .NET Core pozwala na tworzenie aplikacji w dwóch UI architectural design patterns - MVVM (Razor Pages) i MVC. My skupimy się na MVC, które jest już established technologią.
MVC to skrót od Model-View-Controller.
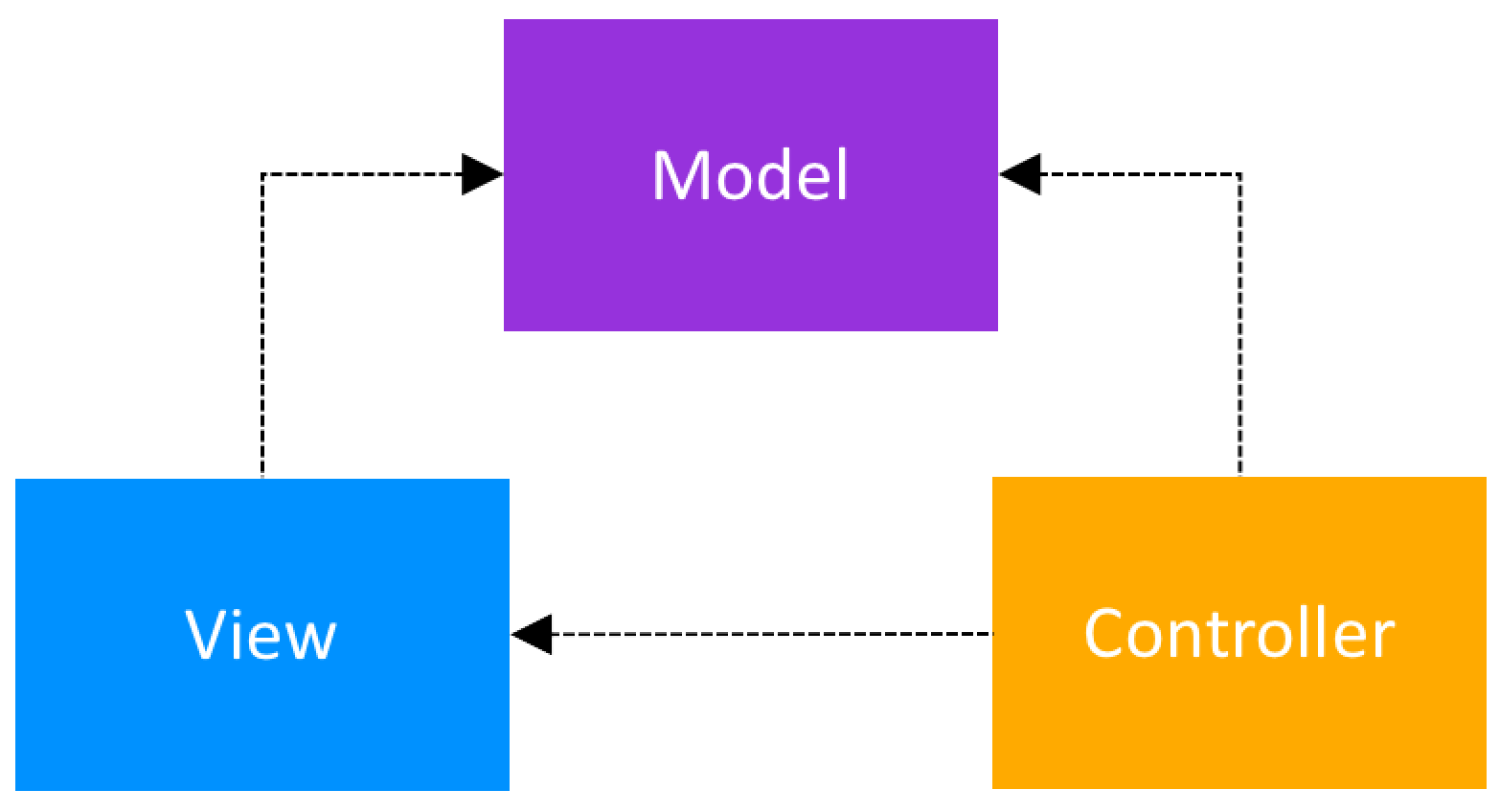
- Model - zawiera logikę biznesową i reprezentuje domenę aplikacji;
- View - wyświetla model i zajmuje się szeroko rozumianą prezentacją danych;
- Controller - reaguje na input użytkownika, wysyłając w odpowiedzi odpowiednie widoki lub informując o tym Model.
W ASP .NET MVC widoki to widoki, kontrolery to kontrolery, a model to cała aplikacja pod spodem. Można go podzielić na kilka warstw (np. serwisy i repozytorium).
4.7 Kontrolery i routing
Każdy kontroler ma publiczne metody, zwane akcjami. Każda z nich reprezentuje pewien HTTP request, w przypadku aplikacji UI z reguły GET lub POST. Domyślnie odwołanie się do adresu http://myapp.com/Controller/Action wywoła akcję o nazwie Action w kontrolerze o nazwie Controller. Taka akcja zwraca pochodną ActionResult, która jest wysyłana do klienta. Najczęściej będzie to widok w przypadku apki webowej.
Routing można dowolnie zmieniać i tworzyć własne reguły co i na co jest mapowane.
4.8 Widoki
Widoki są pisane w HTML-u z Razorem (rozszerzenie .cshtml), który pozwala na wykonanie kodu w C# podczas generowania HTML-a. Podstawową częścią danego widoku jest Model do niego przekazany. Z reguły nie jest on tożsamy z Modelem z MVC - stanowi tylko jakiś snapshot danych wyciągniętych z bazy danych i przedstawionych w przystępnej formie użytkownikowi. Z tego też powodu często mówi się na nie ViewModels.
Przykładowy widok w .cshtml może wyglądać np. tak:
@{
ViewData["Title"] = "Home Page";
}
@model IEnumerable<DuckViewModel>
<h1 class="text-center">Ducks</h1>
<hr />
<div class="align-items-center" style="margin-bottom: 100px">
<table class="table" style="margin-left: auto; margin-right: auto">
<thead>
<tr>
<th>Name</th>
<th>Owner name</th>
</tr>
</thead>
@foreach (var duck in Model)
{
<tr>
<td>@duck.Name</td>
<td>@duck.UserName</td>
</tr>
}
</table>
</div>
<form asp-action="Create" asp-controller="Duck" method="get">
<button class="btn btn-primary float-right", type="submit">
Create a new duck
</button>
</form>
Uważny słuchacz zauważy brak takich tagów jak <body> czy <head>. To dlatego, że w pliku _ViewStart.cshtml, który zostaje wczytany na samym początku tworzenia widoku, ustawiony został Layout.
<!-- _Layout.cshtml -->
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>@ViewData["Title"] - Ducker</title>
<environment include="Development">
<link rel="stylesheet" href="~/lib/bootstrap/dist/css/bootstrap.css" />
</environment>
<!-- ... -->
<link rel="stylesheet" href="~/css/site.css" />
</head>
<body>
<header>
<nav class="navbar navbar-expand-sm navbar-toggleable-sm navbar-light bg-white border-bottom box-shadow mb-3">
<div class="container">
<!-- ... -->
</div>
</nav>
</header>
<div class="container">
<main role="main" class="pb-3">
@RenderBody()
</main>
</div>
<footer class="border-top footer text-muted">
<div class="container">
© 2019 - Ducker - <a asp-area="" asp-controller="Home" asp-action="Privacy">Privacy</a>
</div>
</footer>
<environment include="Development">
<script src="~/lib/jquery/dist/jquery.js"></script>
<script src="~/lib/bootstrap/dist/js/bootstrap.bundle.js"></script>
</environment>
<!-- ... -->
<script src="~/js/site.js" asp-append-version="true"></script>
@RenderSection("Scripts", required: false)
</body>
</html>
Nasz widok jest wklejany tam, gdzie @RenderBody().
4.9 Formularze i walidacja
Aby stworzyć np. nową kaczkę, musimy stworzyć kontroler, który przekaże użytkownikowi odpowiedni widok. Na tym widoku musi znajdować się formularz z danymi kaczki i przycisk do submitu. Tenże przycisk wywoła inną akcję w kontrolerze, która zapisze kaczkę i przekieruje użytkownika z powrotem na stronę główną.
Napiszmy więc kontroler, będzie potrzebował od nas repozytorium i dwóch akcji Create - jednego GET-a, który zwróci formularz, i jednego POST-a, który przyjmie wypełnione dane kaczki i zapisze ją do repozytorium.
public class DuckController : Controller
{
private readonly IRepository _repository;
public DuckController(IRepository repository)
{
_repository = repository;
}
public ActionResult Create() => View(new CreateDuckViewModel());
[HttpPost]
[ValidateAntiForgeryToken]
public async Task<ActionResult> Create(CreateDuckViewModel duck)
{
_repository.Ducks.Add(new Duck { Name = duck.Name, Color = duck.Color});
await _repository.SaveChangesAsync();
return RedirectToAction("Index", "Home");
}
}
Upewnijmy się szybko, że skonfigurowaliśmy nasze repozytorium. W ASP .NET mamy statyczną klasę Startup, której metody są wywoływane przy konfiguracji serwera. Znajdziemy tam metodę ConfigureServices(IServiceCollection services), służącą do skonfigurowania DI.
/* ... */
services.AddDbContext<DuckerDbContext>(options =>
options.UseNpgsql(Configuration.GetConnectionString("DefaultConnection")));
services.AddScoped<IRepository, DuckerDbContext>();
services.AddMvc().SetCompatibilityVersion(CompatibilityVersion.Version_2_2);
/* ... */
Configuration odwołuje się do pliku appsettings.json. Tam znajdziemy element "ConnectionStrings":
"ConnectionStrings": {
"DefaultConnection": "Host=localhost;Port=5432;Database=ducker_db;UserId=postgres;Password=postgres"
}
Wszystko wygląda w porządku, stwórzmy teraz model. Będziemy potrzebowali drop-down menu z dostępnymi kolorami. Posłużą nam do tego obiekty SelectListItem.
public class CreateDuckViewModel
{
public string Name { get; set; }
public string Color { get; set; }
public List<SelectListItem> Colors { get; }
public Color ColorAsEnum => Enum.Parse<Color>(Color);
public CreateDuckViewModel()
{
var colorsArray = Enum.GetNames(typeof(Color));
Colors = colorsArray.Select(c => new SelectListItem(c, c)).ToList();
}
}
Napotykamy na standardowy kłopot HTML-a - jest statyczny i nie ma pojęcia o naszym kodzie w C# i naszych ładnych enumach. Musi operować na stringach, musimy więc przerobić nasz enum na stringi, a potem wynikowy string z powrotem na enum.
Teraz przydałaby się nam walidacja. W ASP .NET osiągamy to za pomocą atrybutów. Atrybutów do walidacji jest cała masa, a nawet jeśli nie ma takiego, jakiego byśmy chcieli, to możemy sobie
a) napisać własny i połączyć z JS-em na fronice,
b) użyć RemoteAttribute, który przyjmuje akcję kontrolera zwracającą true lub false.
Pododawajmy więc sobie jakieś atrybuty.
[Display(Name = "Create duck.")]
public class CreateDuckViewModel
{
[Display(Name = "Name")]
[MaxLength(32)]
[Required]
[RegularExpression(@"^(\p{L}+\s?)*$")]
public string Name { get; set; }
[Display(Name = "Color")]
[Required]
public string Color { get; set; }
public List<SelectListItem> Colors { get; }
public Color ColorAsEnum => Enum.Parse<Color>(Color);
public CreateDuckViewModel()
{
var colorsArray = Enum.GetNames(typeof(Color));
Colors = colorsArray.Select(c => new SelectListItem(c, c)).ToList();
}
}
Jesteśmy gotowi do stworzenia widoku.
@model Ducker.Models.CreateDuckViewModel
@{
ViewData["Title"] = "Create a duck";
}
<h4>@Html.DisplayNameFor(model => model)</h4>
<hr/>
<div class="row">
<div class="col-md-4">
<form asp-action="Create">
<div class="form-group">
<label asp-for="Name"></label>
<input asp-for="Name" class="form-control"/>
<span asp-validation-for="Name" class="text-danger"></span>
</div>
<div class="form-group">
<label asp-for="Color"></label>
<select asp-for="Color" asp-items="Model.Colors" class="form-control"></select>
<span asp-validation-for="Color" class="text-danger"></span>
</div>
<div class="form-group">
<input type="submit" value="Create" class="btn btn-primary"/>
</div>
</form>
</div>
</div>
<div>
<a asp-action="Index" asp-controller="Home">Back to List</a>
</div>
@section Scripts {
@{await Html.RenderPartialAsync("_ValidationScriptsPartial");}
}
4.10 Identity
ASP .NET Core pozwala na zupełnie bezbolesne zintegrowanie systemu kont z naszą aplikacją. Wystarczy dopisać magiczne linijki w Startup.ConfigureServices
services.AddDefaultIdentity<IdentityUser>()
.AddRoles<IdentityRole>()
.AddRoleManager<RoleManager<IdentityRole>>()
.AddDefaultUI(UIFramework.Bootstrap4)
.AddEntityFrameworkStores<DuckerDbContext>();
i w Configure
app.UseAuthentication();
Dodatkowo nasza baza danych powinna dziedziczyć po IdentityDbContext, który ma już odpowiednie tabele skonfigurowane.
Teraz możemy zabezpieczyć nasze akcje Create przed dostępem z zewnątrz, oznaczając je atrybutem AuthorizedAttribute, który nie wpuszcza użytkowników niezalogowanych. Można ten mechanizm rozszerzyć o blokowanie użytkowników nienależących do konkretnych ról, np. nieadminów.
4.11 Co dalej?
ASP .NET jest oczywiście o wiele potężniejszym narzędziem niż tylko maszynką do routingu i generowania widoków. W Startup możemy sobie skonfigurować cały request pipeline - po kolei wszystkie kroki, które nasza aplikacja wykonuje na requeście i responsie. Tag helpery, które już widzieliśmy w postaci asp-for i asp-action/asp-controller pozwalają na proste tworzenie skomplikowanych kontrolek z JS-em w środku. No ale na więcej zabawy nie starczy nam czasu.
5. Jak działa Entity Framework?
Entity Framework to ORM - Object-Relational Mapping. Służy do połączenia interfejsem środowiska .NET z relacyjną bazą danych. EF korzysta z trzech rzeczy:
- Model bazy danych - metadane, mówiące EF o bazie danych, z którą się łączy; tabele, relacje, constrainty, indexy etc.;
- Encje - obiekty .NET-owe reprezentujące rekordy w bazie;
- LINQ to SQL - zintegrowany z C# język zapytań.
5.1 Konfiguracja bazy - encje i metadane
Istnieją dwa podejścia do pracy z EF: database-first i code-first. Database-first zakłada, że mamy gotową bazę danych i próbujemy zbudować na niej aplikację. Code-first zakłada, że kod naszej aplikacji i obiekty C# determinują wygląd bazy danych. There are arguments for both, tutaj będziemy zajmować się wyłącznie code-first.
Potrzebujemy stworzyć pustą bazę danych, skonfigurować ASP .NET, aby się do niej łączył i zacząć tworzyć klasy.
EF potrzebuje klas reprezentujących encje oraz klasy dziedziczącej po DbContext. To ona ma połączenia do bazy danych i udostępnia tabele w postaci właściwości DbSet<T> (implementujących IQueryable<T>).
Spróbujmy stworzyć przykładowy model bazy, mając w ręku ASP .NET Identity i wiedząc, że konta użytkownika są reprezentowane przez IdentityUser z PK na Id.
namespace Ducker.Data.Enums
{
public enum Color
{
Yellow,
Green,
Red,
Blue
}
}
// Entities/Duck.cs
using Ducker.Data.Enums;
using Microsoft.AspNetCore.Identity;
namespace Ducker.Data.Entities
{
public class Duck
{
public string Name { get; set; }
public int TimesSqueaked { get; set; }
public Color Color { get; set; }
public string UserId { get; set; }
public IdentityUser User { get; set; }
}
}
Tutaj widzimy, w jaki sposób konfigurowane są relacje między encjami: tzw. navigation properties, które są po prostu propertką będącą referencją na related entity w przypadku relacji to-one, a kolekcją referencji w przypadku relacji to-many. Trzymamy też sam FK jako UserId dla wygody.
Aby przygotować constrainty etc. dla naszej bazy danych, musimy przeładować metodę DbContext.OnModelCreating(ModelBuilder) oraz dodać odpowiedni DbSet.
using Ducker.Data.Entities;
using Microsoft.AspNetCore.Identity.EntityFrameworkCore;
using Microsoft.EntityFrameworkCore;
namespace Ducker.Data
{
public class ApplicationDbContext : IdentityDbContext
{
public DbSet<Duck> Ducks { get; set; }
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options)
: base(options)
{
}
protected override void OnModelCreating(ModelBuilder builder)
{
base.OnModelCreating(builder);
builder.Entity<Duck>(
entity =>
{
entity.HasKey(e => e.Name);
entity.Property(e => e.Name)
.HasMaxLength(32)
.IsRequired();
entity.Property(e => e.Color)
.IsRequired();
entity.Property(e => e.TimesSqueaked)
.HasDefaultValue(0)
.IsRequired();
entity.HasOne(e => e.User)
.WithMany()
.HasForeignKey(e => e.UserId);
});
}
}
}
Rzeczy związane z Identity są już skonfigurowane w IdentityDbContext. Teraz wystarczy wygenerować migrację, zaaplikować ją do bazy danych i ją podejrzeć. Zobaczymy tabelę wyglądającą tak:
CREATE TABLE "Ducks"
(
"Name" VARCHAR(32) NOT NULL
CONSTRAINT "PK_Ducks"
PRIMARY KEY,
"TimesSqueaked" INTEGER DEFAULT 0 NOT NULL,
"Color" INTEGER NOT NULL,
"UserId" TEXT
CONSTRAINT "FK_Ducks_AspNetUsers_UserId"
REFERENCES "AspNetUsers"
ON DELETE RESTRICT
);
ALTER TABLE "Ducks"
OWNER TO postgres;
CREATE INDEX "IX_Ducks_UserId"
ON "Ducks" ("UserId");
EF postanowił zrobić sobie indeks na FK, no niech mu będzie. Oczywiście mamy na to wpływ, możemy poprosić o inny indeks używając HasIndex. Dzięki FluentAPI możemy praktycznie dowolnie skonfigurować bazę danych. Stored procedures też się da, ale to poza zakresem prezentacji.
Słowo o migracjach: są to po prostu instrukcje dla bazy danych w jaki sposób zaktualizować model bazy i jak to potem cofnąć (prof. Stencel wbiega do sali krzycząc EWOLUCJA MODELU!). Domyślnie zablokowane jest tworzenie migracji, które spowodowałyby utratę danych (i bardzo dobrze).
5.2 LINQ
Najlepszą część C# zostawiliśmy sobie na koniec. Language Integrated Query - LINQ (czyt. link) - to język zapytań do przetwarzania potokowego kolekcji w C#. Jest to zbiór extension methods zdefiniowanych na IEnumerable (LINQ to Objects), plikach XML (LINQ to XML) oraz bazach pod Entity Frameworkiem (LINQ to Entities).
Zakładając źródło postaci IEnumerable<TSource>, podstawowe operacje to:
5.3 Select - projekcja
IEnumerable<U> Select(Func<TSource, U>) pozwala na transformację danych. Funkcja jest wywoływana dla każdego elementu i zwracany jest enumerable wyników.
var ducks = new List<Duck>
{
new Duck("Jacuś"),
new Duck("Piotruś"),
new Duck("Azathoth")
};
foreach(var name in ducks.Select(d => d.Name))
{
Console.WriteLine(name);
}
> Jacuś
> Piotruś
> Azathoth
5.4 Where - selekcja/filtrowanie
IEnumerable<TSource> Where(Func<T, bool>) zwraca elementy spełniające dany predykat.
var values = new[] { 7, 42, 21, 1, 8 };
foreach(var val in values.Where(v => v >= 8))
{
Console.WriteLine(val);
}
> 42
> 21
> 8
5.5 SelectMany - spłaszczenie
IEnumerable<TResult> SelectMany(Func<TSource, IEnumerable<TResult>) wyłuskuje enumerable wyników z każdego elementu i łączy (spłaszcza) je w jeden.
var ducks = new List<Duck>
{
new Duck("Jacuś"),
new Duck("Piotruś")
};
foreach(var letter in ducks.SelectMany(d => d.Name.ToCharArray()))
{
Console.WriteLine(letter);
}
> J
> a
> c
> u
> ś
> P
> i
> o
> t
> r
> u
> ś
5.6 GroupBy - grupowanie
IEnumerable<IGrouping<TKey, TSource>> GroupBy(Func<TSource, TKey>) grupuje po kluczu; ma wiele przeładowań, może automatycznie robić projekcję wynikowych grupowań i stosować customowe komparatory.
var ducks = new List<Duck>
{
new Duck("Jacuś", Color.Yellow),
new Duck("Piotruś", Color.Red),
new Duck("Jacuś", Color.Green)
};
foreach(var grouping in ducks.GroupBy(d => d.Name))
{
Console.WriteLine($"Ducks with name {grouping.Key}:");
foreach(var duck in grouping)
{
Console.WriteLine($"{duck.Name}, {duck.Color} color");
}
}
> Ducks with name Jacuś:
> Jacuś, Yellow color
> Jacuś, Green color
> Ducks with name Piotruś:
> Piotruś, Red color
5.7 OrderBy, ThenBy - sortowanie
IOrderedEnumerable<TSource> OrderBy(Func<TSource, TKey>) - sortowanie po kluczu; na wynikowym IOrderedEnumerable można zastosować ThenBy(Func<TSource, TKey>, żeby posortować po drugiej (trzeciej, czwartej…) wartości.
var ducks = new List<Duck>
{
new Duck("Jacuś"),
new Duck("Piotruś"),
new Duck("Azathoth"),
new Duck("Psuchawrl")
};
foreach(var duck in ducks.OrderBy(d => d.Name[0]).ThenBy(d => d.Name.Length))
{
Console.WriteLine(duck.Name);
}
> Azathoth
> Jacuś
> Piotruś
> Psuchawrl
Wariantem są OrderByDescending oraz ThenByDescending.
5.8 Join
Join(IEnumerable<TInner>, Func<TSource,TKey>, Func<TInner,TKey>, Func<TSource,TInner,TResult>) złącza dwa enumerable po kluczach i produkuje rezultat dla każdych dwóch zmatchowanych elementów.
var ducks = new List<Duck>
{
new Duck("Jacuś", Color.Yellow),
new Duck("Jacuś", Color.Green),
new Duck("Piotruś", Color.Yellow)
};
foreach(var (name, colorA, colorB) in ducks.Join(ducks, d => d.Name, d => d.Name, (d1, d2) => (d1.Name, d1.Color, d2.Color)))
{
Console.WriteLine($"{name}: {colorA} - {colorB}");
}
> Jacuś: Yellow - Yellow
> Jacuś: Yellow - Green
> Jacuś: Green - Yellow
> Jacuś: Green - Green
> Piotruś: Yellow - Yellow
5.9 Inne
Distinct, można podać własny komparator;Skip(int)- wyrzuca n elementów z początku;SkipLast(int)- wyrzuca, ale z końca;SkipWhile(Func<TSource, int, bool>)- wyrzuca dopóki predykat jest spełniony;Take- tak jak skip, tylko wybiera elementy zamiast wyrzucaćUnion,Intersect,Except- suma, przecięcie, różnica dwóch enumerabliZip- splot, takiSelectna dwóch enumerablach jednocześnie
5.10 Deferred execution
Wszystkie powyższe metody tak naprawdę się nie wykonują. LINQ buduje sobie plan wykonania zbudowanego query i wykona go dopiero przy enumeracji, to znaczy po wrzuceniu do foreacha albo wykonaniu jednej z operacji, które już muszą zostać wykonane natychmiastowo (agregacje i budowanie kolekcji).
Warto o tym pamiętać, po pierwsze dzięki temu można sobie złożyć zapytanie bardzo szybko z gotowych klocków i odpalić je asynchronicznie. Po drugie należy bardzo unikać tzw. multiple enumerations, przykładowo taki kod:
var ducks = new List<Duck>
{
/* ... */
}
var names = ducks.Select(d => d.Name); // Deffered, no projection happens here.
foreach(var name in ducks) // Enumeration, the query fires.
{
Console.WriteLine(name);
}
foreach(var name in ducks) // Another enumeration, another execution.
{
/* ... */
}
wywołuje selekcję dwa razy. Wystarczy sobie wyobrazić, że koszt wywołania tamtej metody jest bardzo duży, albo np. operujemy na tabeli w bazie danych i robimy dwa zapytania z tym samym wynikiem zamiast jednego.
Wszystkie kolejne operacje LINQ wymienione w tej prezentacji powodują immediate execution.
5.11 ToList - execute!
Klasyka gatunku, jedna z najczęściej używanych operacji. Kiedy chcemy wykonać swoje query i zapisać wynik w List<TResult> wywołujemy ToList(). Można tym też przerobić dowolny IEnumerable na listę, np. Array czy Dictionary.
Koledzy ToList to:
ToArrayToDictionaryToHashSetToLookup
5.12 Agregacje
int Max(Func<TSource, int>),
int Min(Func<TSource, int>),
int Sum(Func<TSource, int>),
int Average(Func<TSource, int>)
TResult Aggregate(TResult, Func<TResult, TSource, TRessult>) agregują enumerable i zwracają odpowiednio maksimum, minimum, sumę, średnią i dowolną customową agregację.
Istnieją warianty Max, Min, Sum i Average dla wszystkich bazowych typów numerycznych.
var ducks = new List<Duck>
{
new Duck("Jacuś"),
new Duck("Piotruś"),
new Duck("Azathoth"),
new Duck("Psuchawrl")
};
Console.WriteLine(ducks.Aggregate(0, (a, d) => (a + d.Name.Length) % 2));
> 1
5.13 First, Last, Single
TSource First(), TSource First(Func<TSource, bool>)
TSource Last(), TSource Last(Func<TSource, bool>)
TSource Single(), TSource Single(Func<TSource, bool>)
Wybiera odpowiednio pierwszy, ostatni i jedyny element spełniający dany predykat. Jeśli taki element nie istnieje, rzuca InvalidOperationException.
W przypadku Single, jeśli istnieje więcej niż jeden taki element, również rzuca InvalidOperationException.
Istnieją warianty FirstOrDefault, LastOrDefault, SingleOrDefault, które nie rzucają wyjątku w postaci nieznalezienia żadnego elementu, tylko zwracają default(TSource).
var ducks = new List<Duck>
{
new Duck("Jacuś"),
new Duck("Piotruś"),
new Duck("Azathoth"),
new Duck("Psuchawrl")
};
var firstLong = ducks.First(d => d.Name.Length > 7);
Console.WriteLine(firstLong.Name);
> Azathoth
5.14 Empty
True jeśli enumerable pusty, false otherwise. Nuff said.
5.15 Count
Zwraca liczbę elementów. Tutaj w szczególności zwróćmy uwagę na deferred execution.
var src = _repository.Ducks;
for(var i = 1; i <= src.Count(); ++i)
{
/* ... */
}
for(var i = 1; i <= src.Count(); ++i)
{
/* ... */
}
Powyższy kod powoduje dwa wykonania LINQ i jeśli _repository jest podłączone do bazy danych, to wykona dwa zapytania.
Dodatkowo używanie Count do sprawdzenia pustości, czyli
var isEmpty = src.Count() == 0;
jest skrajnie nieinteligentne, bo zajmuje czas liniowy od wielkości kolekcji.
5.16 All, Any
Sprawdza, czy predykat zachodzi dla każdego/jakiegokolwiek elementu. Oczywiście nie jest głupie i breakuje wcześnie jeśli odpowiedź jest ustalona.
5.17 Query syntax
LINQ można też stosować z pseudo-SQLową składnią. Przykładowo:
var result = ducks
.Where(d => d.Data.Name.Length >= 8)
.OrderByDesc(d => d.Data.Name.Length)
.Select(d => new {d.Data.Name.Length, d.Color});
to to samo co
from duck in ducks
where duck.Data.Name.Length >= 8
orderby duck.Data.Name.Length descending
select new {duck.Data.Name.Length, duck.Data.Color}
W przypadku banalnych query, jak list.Where(sth), lepiej użyć method syntax. Im bardziej skomplikowane query, tym większa szansa że query syntax będzie czytelniejszy. Pozwala on też na wprowadzanie tzw. transparent identifiers
from duck in ducks
let length = duck.Data.Name.Length
where length >= 8
orderby length descending
select new {Length = length, duck.Data.Color}
5.18 LINQ to Entities
Jeśli będziemy wywoływać LINQ na DbSetach, to wykonanie query spowoduje wysłanie zapytania do bazy danych. Przykładowo
var theYellowDuckNames = ducks
.Where(d => d.Color == Color.Yellow)
.Select(d => d.Name)
.ToList();
wywoła SQL
SELECT d."Name"
FROM "Ducks" AS d
WHERE d."Color" = 0
Include
Zamiast robić joiny, możemy wywoływać domyślne joiny po FK za pomocą Include. Jeśli nie dodamy żadnego Include, standardowo wszystkie navigation properties będą puste, to znaczy kolekcje puste, pojedyncze referencje równe null. Jeśli dodamy Include na tej property, wygeneruje się SQL z odpowiednim Joinem.
ducks.Include(d => d.User).Select(d => (d.Name, d.User.UserName));
SELECT d."Name", "d.User"."UserName"
FROM "Ducks" AS d
LEFT JOIN "AspNetUsers" AS "d.User" ON d."UserId" = "d.User"."Id"
Insert, Update, Delete
Jako że DbSet to kolekcja typów referencyjnych, to dodanie do niej nowej encji, zmodyfikowanie z niego wyjętej lub usunięcie spowoduje aktualizację bazy. Nie od razu co prawda, najpierw trzeba wywołać SaveChanges(), które wykonuje wszystkie te operacje w jednej transakcji.
Async
Wszystkie operacje LINQ to Entities, które powodują wykonanie query, mają swoje asynchroniczne odpowiedniki. Jest więc ToListAsync(), SingleAsync(Func<TSource, bool>), SaveChangesAsync() etc. i to nich powinno się używać.
6. Przykładowa apka.
Teraz pokażemy apkę stworzoną w ASP .NET Core z Identity i EF Core w dosłownie pół godziny.
Aby postawić apkę lokalnie należy sklonować repozytorium z http://github.com/V0ldek/Ducker i skonfigurować swoje środowisko.
Instalacja na Windowsie:
- Pobieramy i instalujemy Visual Studio Community.
- Instalujemy rozszerzenie ReSharper (wymaga licencji).
- Instalujemy bazę danych PostgreSQL
- port 5432
- konto superusera
postgres, hasłopostgres
- Uruchamiamy narzędzie
psql.exez PowerShella (najpierw należy je dodać do zmiennej środowiskowejPATH, wchodząc w Zaawansowane ustawienia systemu/Zmienne środowiskowe, tool znajduje się w katalogu instalacji PostgreSQL/bin) piszącpsql -U postgres. - Po podaniu hasła wklepujemy zaklęcie
CREATE DATABASE ducker_db;. - Uruchamiamy solucję w VisualStudio (plik Ducker.sln w repo).
- Teraz musimy skonfigurować bazę danych. Uruchamiamy Package Manager Console (pasek na dole lub Tools/NuGet Package Manager/Package Manager Console) i piszemy zaklęcie
Update-Database, które zastosuje wszystkie migracje do naszej lokalnej bazy danych. - O ile wszystko się udało powinniśmy teraz móc odpalić aplikację wybierając IIS Express i klikając w przycisk z zielonym trójkącikiem na górze.
Na Linuxie (disclaimer, nie testowałem czy to działa, nigdy nie korzystałem z .NET Core’a na Linuxie, to jest prawie tak samo nierozsądne jak pisanie w C na Windowsie):
- https://www.ostechnix.com/how-to-install-microsoft-net-core-sdk-on-linux/
- Wybieramy swój edytor, jedyne sensowne opcje to VisualStudio Code i Rider od JetBrainsów.
- Instalujemy bazę PostgreSQL tak jak na Windowsie, uruchamiamy
psqlw terminalu i tworzymy bazę danychducker_db. - Stosujemy migracje używając .NET Core CLI i zaklęcia
dotnet ef database update. W przypadku kłopotów konsultujemy się z MSDN-em - Żeby móc hostować naszą aplikację musimy użyć jakiegoś silnika. Da się to zrobić Dockerem, Nginxem albo Apachem, najlepiej poczytać na MSDN-ie.
Przetestujmy apkę tworząc nowe konto użytkownika i tworząc nową kaczkę.
Rola Administrator jest skonfigurowana w metodzie Startup.CreateRoles. W linijce 95 można zmienić nazwę użytkownika admina, np. na swoją. Administrator widzi kaczki wszystkich użytkowników, zwykły użytkownik tylko swoje.
Jako ćwiczenie: dodaj funkcjonalność edytowania istniejącej kaczki. Obok każdego wpisu w tabelce na stronie głównej powinien pojawić się przycisk edycji, przekierowujący do formularza edycji (prawdopodobnie pod /Duck/Edit?Name=...). Wysłanie tego formularza powinno poskutkować zapisaniem zmian w bazie danych.
Koniec
Dziękuję za uwagę.
Copyright © Mateusz Gienieczko 2019-2020