Czy zastanawialiście się kiedyś…
- w jaki sposób po naciśnięciu przycisku komputer potrafi uruchomić system operacyjny?
- gdzie zapisane są pierwsze instrukcje?
- jakie zadania realizuje BIOS?
- jaka jest definicja i etymologia słowa booting?
Na ostatnie pytanie odpowiemy od razu, a resztę wątpliwości wyjaśni poniższy scenariusz do dzisiejszych zajęć.
Booting to sekwencja operacji, które doprowadzają do pełnego uruchomienia komputera i załadowania systemu operacyjnego do pamięci operacyjnej. Samo pojęcie jest skrótem od angielskiego słowa bootstrapping. Nawiązuje ono do wyrażenia: pull oneself over a fence by one's bootstraps, które przenośnie oznacza samodoskonalenie się bez pomocy z zewnątrz. Ukryte znaczenie tego słowa opisuje więc świetnie ideę uruchamiania komputera: najpierw wykonywane są proste, niskopoziomowe programy, które ładują coraz to bardziej skomplikowany i abstrakcyjny kod – komputer doskonali sam siebie.
1. Uruchamiamy system
Tuż po włączeniu zasilania płyta główna uruchamia wbudowane oprogramowanie (firmware) oraz inicjuje działanie jednego z procesorów (BSP – bootstrap procesor). Wybrany procesor będzie wykonywał instrukcje potrzebne do pełnego uruchomienia systemu, a sposób jego funkcjonowania jest kluczowy dla całego procesu. Z tego właśnie powodu wsteczna kompatybilność procesorów produkowanych przez firmę Intel uczyniła bootstrapping dość skomplikowaną operacją.
Procesory Intela (oraz innych firm produkujących procesory o tej samej architekturze) zachowują wsteczną kompatybilność z modelem 8086 z 1978 roku, o 16-bitowej architekturze i 1 MiB przestrzeni adresów fizycznych. To oznacza, że współczesne procesory są w stanie obsługiwać oprogramowanie sprzed czterech dekad! Aby zrealizować ten cel, procesor, zaczynając swoją pracę, emuluje dawne urządzenie i nakłada na siebie sztuczne ograniczenia (tak – wszystko po to, aby móc uruchomić np. 86-DOS-a). Ten specyficzny tryb funkcjonowania procesora nazywamy trybem rzeczywistym (ang. real mode).
1.1. Tryb rzeczywisty
Na początku tryb rzeczywisty był jedynym trybem procesora i systemy operacyjne, zaprojektowane pod kątem ówczesnego sprzętu o względnie słabych parametrach jak na obecne wymagania, korzystały z tego trybu. Współczesne systemy działają w trybie chronionym (ang. protected mode), który pozwala na pełne wykorzystanie mechanizmów i zasobów aktualnie oferowanych przez sprzęt. Określenie „tryb chroniony” nawiązuje do jednej z najważniejszych cech, która odróżnia ten tryb od trybu rzeczywistego: ochrona pamięci (w trybie chronionym proces może odwoływać się tylko do pamięci, która została mu przydzielona).
Poza brakiem ochrony pamięci, wadami trybu rzeczywistego są:
- brak mechanizmu pamięci wirtualnej i stronicowania (o których wkrótce będzie mowa na wykładzie),
- niewielki rozmiar wartości, na których operuje procesor: 16 bitów,
- możliwość zaadresowania jedynie ok. 1 MiB pamięci.
Dla programisty szczególnie bolesny w trybie rzeczywistym może być sposób adresowania pamięci. Wszystko dlatego, że inżynierowie Intela zaprojektowali architekturę procesora 8086 z myślą o 1 MiB przestrzeni adresów (220 adresów) i jednocześnie możliwości automatycznego przenoszenia na tę architekturę kodu 8-bitowych procesorów 8080/8085 (o 16-bitowych adresach), a jednocześnie uznali 20-bitowe rejestry za niepraktyczne. W efekcie 16-bitowy rejestr Intela 8086 mógł zaadresować tylko 64 KiB pamięci. Rozwiązaniem, które zaimplementowano z myślą o możliwości adresowania całego 1 MiB, była segmentacja pamięci.
Wspierając segmentację pamięci, procesor dysponuje dodatkowymi rejestrami – rejestrami segmentowymi:
| rejestr | przeznaczenie |
|---|---|
cs |
code segment wskazuje na aktualnie wykonywany segment kodu jest używany razem z rejestrem ip, aby wskazać adres kolejnej instrukcji do wykonania
|
ds |
data segment wskazuje na aktualny segment z danymi, zwykle zawierający zmienne globalne i statyczne aktualnie wykonywanego programu |
es |
extra segment wskazuje na pomocniczy segment danych, służy głównie do przenoszenia danych pomiędzy różnymi segmentami, ułatwia implementację, gdy program potrzebuje więcej niż 64 KiB pamięci na dane |
ss |
stack segment wskazuje na segment zawierający stos aktualnie wykonywanego programu wierzchołek stosu znajduje się pod adresem ss:sp
|
fs | general purpose segment dodatkowy segment danych wprowadzony od procesora 80386 |
gs | general purpose segment dodatkowy segment danych wprowadzony od procesora 80386 |
Każdy adres składa się z wartości dwóch rejestrów: rejestru segmentowego
(np. ds) oraz rejestru z przesunięciem (ang. offset),
(np. bx). Adresy są zapisywane w postaci segment:offset,
np. 12ab:34cd, a ich wartość jest obliczana zgodnie ze wzorem
address = segment * 16 + offset.
W naszym przykładzie 12ab:34cd oznacza więc adres
0x12ab0 + 0x34cd = 0x15f7d.
Zwróćmy uwagę, że do danego segmentu można maksymalnie przypisać 64 KiB adresów oraz że jeden adres fizyczny może być reprezentowany przez różne adresy postaci segment:offset. Na przykład, adres fizyczny 0x210 da się wyrazić jako 0020:0010, 0000:0210, 001b:0060 itd.
Pisząc kod, nie trzeba wskazywać segmentów jawnie – procesor domyśla się (czasem niesłusznie), do którego segmentu chcemy się odwołać:
mov [si], ax ; procesor zapisze wartość z rejestru ax pod adresem ds:si
mov es:[si], ax ; procesor zapisze wartość z rejestru ax pod adresem es:si
mov [bp + 0], ax ; procesor zapisze wartość z rejestru ax pod adresem ss:bp
Wystarczy więc, że na początku programu ustawimy odpowiednie wartości segmentów, a później będziemy w świadomy sposób korzystać z instrukcji asemblera.
Skoro wiemy już, jak zaadresować 1 MiB – czy to oznacza, że boot loader w trybie rzeczywistym może skorzystać z takiej ilości RAM-u? Niestety. We wczesnych systemach (i w fazie bootowania) jedynie 640 KiB adresów odnosi się do pamięci operacyjnej. Pozostałe adresy są mapowane na urządzenia lub inne rodzaje pamięci, m.in. pamięć nieulotną, która (inaczej niż RAM) zachowuje zawartość bez potrzeby ciągłego zasilania i w której znajduje się firmware (tak naprawdę kod firmware, ze względu na czas dostępu, jest po włączeniu zasilania kopiowany do RAM-u).
1.2. BIOS
Pierwszym programem, który procesor rozpocznie wykonywać po uruchomieniu w trybie rzeczywistym, jest wbudowany na płycie głównej firmware, czyli BIOS (ang. Basic Input/Output System). Narzuca się pytanie: w jaki sposób procesor dowiaduje się, że powinien zacząć pracę właśnie od instrukcji BIOS-u? Uruchomienie właściwego kodu jest możliwe dzięki następującym rozwiązaniom (patrz też Minimal Intel Architecture Boot Loader):
- procesor w trybie rzeczywistym pobiera kolejną instrukcję spod adresu 16*
cs+ip; - wartości rejestrów
csorazipsą ustalane po włączenia zasilania procesora lub po jego wyzerowaniu następująco: rejestripzawiera wartość 0xfff0, a rejestrcsw części widocznej dla programisty (selektor) – wartość 0xf000, w części niewidocznej dla programisty (deskryptor segmentu) – adres bazowy segmentu 0xffff0000 i limit 0xffff; - procesor 8086 miał tylko część widoczną rejestrów segmentowych i pobierał pierwszą instrukcję do wykonania spod adresu 0xffff0;
- współczesne procesory x86 pobierają pierwszą instrukcję, interpretując deskryptor segmentu, czyli spod adresu fizycznego 0xfffffff0, gdzie w kolejnych 16 bajtach musi znaleźć się daleki skok do adresu w obrębie początkowego 1 MiB pamięci, jeśli ładowanie systemu ma być kontynuowane w trybie rzeczywistym, lub przełączenie do trybu chronionego, jeśli ładowanie ma być kontynuowane w tym trybie;
- płyty główne komputerów są tak skonstruowane, że wyżej wspomniane adresy wskazują na pamięć, gdzie znajduje się kod BIOS-u.
Wykonując kod BIOS-u, procesor inicjuje działanie sprzętu i przeprowadza testy POST (ang. Power-on Self Test), których celem jest weryfikacja, czy sprzęt funkcjonuje prawidłowo. BIOS sprawdza m.in. stan:
- rejestrów procesora,
- pamięci (zapis i odczyt),
- szyny adresowej,
- karty graficznej i klawiatury.
Wyniki testów są czasami wyświetlane na ekranie lub (jeśli nie działa karta graficzna) sygnalizowane za pomocą sekwencji błysków lampki czy też sygnałów dźwiękowych. W przypadku wykrycia jakiejkolwiek nieprawidłowości proces bootowania zostaje przerwany.
Jeśli testy POST zakończą się pomyślnie, kolejnymi zadaniami BIOS-u są zainicjowanie tablicy przerwań (po adresem 0), aby możliwe było wywoływanie funkcji BIOS-u, zainicjowanie podstawowych urządzeń wejścia-wyjścia (klawiatura, ekran, dyski), a następnie rozpoczęcie ładowania systemu operacyjnego. Ze względu na swoje ograniczenia BIOS nie może jednak bezpośrednio załadować systemu – to zadanie zostaje przekazane programowi nazywanemu boot loaderem.
Aby znaleźć kod boot loadera, BIOS przegląda zamontowane nośniki danych (np. twardy dysk, CD-ROM), sprawdzając, czy na którymś z nich pierwszy sektor danych (tradycyjnie o rozmiarze 512 bajtów) kończy się magiczną liczbą 0xaa55. Na podstawie tej ustalonej wartości BIOS identyfikuje specjalny sektor MBR (Master Boot Record). Jego klasyczną strukturę przedstawia rysunek poniżej.

Zauważmy, że poza kodem boot loadera oraz magiczną liczbą częścią sektora jest także tablica partycji.
BIOS kończy swoje poszukiwania po znalezieniu pierwszego z boot loaderów i ładuje go do pamięci pod ustalony adres: 0x7c00. Po czym zostaje tam przekazane sterowanie, a procesor zaczyna wykonywać instrukcje boot loadera.
1.3. Boot loader
Od boot loadera oczekujemy wykonania następujących zadań:
- zebranie informacji, których potrzebuje jądro systemu operacyjnego, żeby zacząć pracę,
- wczytanie do pamięci kodu jądra i wszystkich potrzebnych mu danych,
- przekazanie sterowania do jądra.
Ze względu na ilość i skomplikowanie zadań do wykonania boot loader najczęściej nie jest w stanie zmieścić się w przeznaczonym dla niego miejscu w MBR. Wspomniany problem jest rozwiązywany na różne sposoby. Na przykład boot loader dwuetapowy wykorzystuje kod w MBR (I etap) do uruchomienia znacznie większego programu (II etap), który może zrealizować wszystkie z wymienionych zadań.
Warto wiedzieć
Aby rozbudować boot loader o kolejne etapy, trzeba znaleźć na dysku odpowiednie miejsce, w którym zostanie umieszczony dodatkowy kod. To nie jest łatwe: po pierwsze, zlokalizowanie programu nie powinno wymagać znajomości systemu plików; po drugie, trzeba uważać, żeby kod boot loadera czegoś nie nadpisał ani sam nie został później nadpisany. Programiści boot loaderów korzystają często z faktu, że 62 sektory (31 KiB) za MBR są puste – pierwsza partycja ze względu na kompatybilność z DOS-em jest wyrównywana do początku kolejnego cylindra na dysku (manual GRUB-a, The DOS compatibility region) i właśnie w tym miejscu umieszczają dodatkowy kod. Samo pojęcie podziału dysku na cylindry o 63 sektorach jest też zachowywane ze względu na wsteczną kompatybilność – fizyczna organizacja dysku może być zupełnie inna.Inny sposób obejścia niewielkiego rozmiaru MBR wymaga, aby boot loader najpierw przeanalizował tablicę partycji. W tej strukturze znajduje się m.in. informacja, które partycje są bootowalne (czyli zawierają w pierwszym sektorze własny boot loader, najczęściej dedykowany dla konkretnego systemu, zainstalowanego na tej partycji). Boot loader wyświetla wówczas menu, umożliwiając wybór, który system ma zostać uruchomiony. Następnie kopiuje swój kod do innego miejsca w pamięci (tradycyjnie nowym adresem jest 0x0000:0x0600), a pod swój oryginalny adres (0x0000:0x7c00) ładuje boot loader danej partycji, któremu pozostawia do wykonania resztę zadań.
Niewystarczająca przestrzeń przydzielona w ramach MBR jest tylko jedynym z wielu ograniczeń, z którymi boot loader musi się zmierzyć. Zastanówmy się, w jaki sposób boot loader może załadować do pamięci jądro, wiedząc, że:
- w trybie rzeczywistym ma do dyspozycji tylko 640 KiB RAM-u,
- obraz jądra (nawet w postaci skompresowanej) zajmuje więcej niż 640 KiB,
- boot loader musi działać w trybie rzeczywistym, żeby korzystać z BIOS-u, który odczytuje dane z dysku.
Rozwiązaniem jest tzw. tryb nierzeczywisty (ang. unreal mode) – technika, która pojawiła się jako efekt uboczny pamięci podręcznej deskryptorów. W dużym uproszczeniu cała koncepcja polega na wykonaniu następujących kroków:
- boot loader przełącza się do trybu chronionego, w którym ustawia w rejestrze segmentowym (np.
ds) wartość selektora, który wskazuje na deskryptor segmentu rozpoczynającego się pod adresem fizycznym 0 i mającego rozmiar 4 GiB, jak to jest przewidziane w trybie chronionym; - przy okazji tej operacji procesor zapamiętuje aktualne położenie i rozmiar segmentu w niewidocznej dla programisty części rejestru segmentowego (pamięć podręczna deskryptora);
- po powrocie do trybu rzeczywistego pamięć podręczna nie jest nadpisywana, co pozwala na używanie 32-bitowych przesunięć podczas adresowania, a nowym limitem nie jest już 1 MiB lecz 4 GiB przestrzeni adresowej.
Po załadowaniu jądra do pamięci i zaopatrzeniu go w odpowiednie informacje cel boot loadera zostaje osiągnięty. Od tego momentu proces bootowania jest nadzorowany przez jądro danego systemu operacyjnego.
Przykładowo dla systemu Linux i platformy i386 przestrzeń adresowa po załadowaniu jądra do pamięci wygląda zazwyczaj tak, jak prezentuje to rysunek poniżej (adres X jest uzależniony od konkretnego boot loadera).
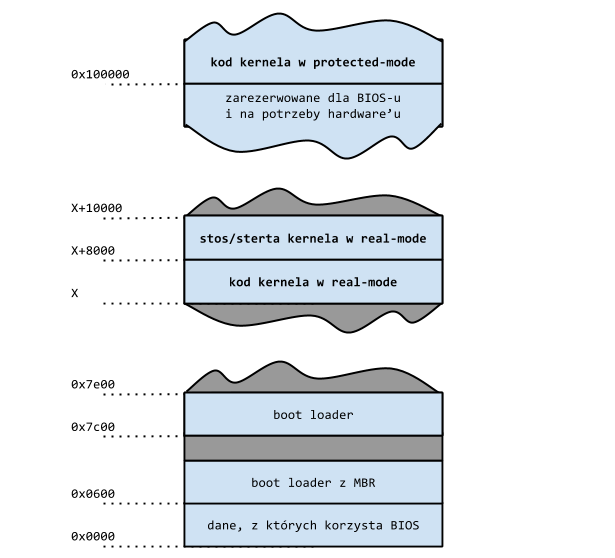
Zauważmy, że obraz jądra Linuxa składa się z dwóch części. Pierwsza z nich (od której zaczyna się wywołanie kodu) załadowana do pamięci poniżej 640 KiB funkcjonuje w trybie rzeczywistym, druga zaś znajduje się powyżej 1 MiB i działa w trybie chronionym.
1.4. Co dalej?
O tym, jak wyglądają dalsze etapy uruchamiania systemu w przypadku Linuxa można przeczytać m.in. na świetnym blogu Gustavo Duarte.
Zdobytą wiedzę warto uzupełnić o informacje na temat popularnych boot loaderów:
oraz na temat UEFI (Unified Extensible Firmware Interface), który jest względnie nowym standardem interfejsu między systemem operacyjnym a firmware'em. UEFI przejmuje część zadań BIOS-u, w szczególności nie powiela ograniczeń związanych ze strukturą MBR, wykonując proces bootowania w inny sposób. O różnicach między BIOS-em a UEFI można przeczytać m.in. na następujących stronach:
2. Modyfikujemy boot loader
Spróbujmy zastąpić oryginalny kod boot loadera spreparowanym przez nas. Zaczniemy od napisania bardzo prostego programu, który zamiast załadować system operacyjny zapętli się w miejscu. Nie tylko działanie naszego boot loadera będzie nieskomplikowane, ale również sposób, w jaki go stworzymy. Głównym celem tej części ćwiczeń jest bowiem zapoznanie się z przydatnymi narzędziami i oswojenie z trybem rzeczywistym.
2.1. Potrzebne narzędzia
dd
Program data duplicator wywoływany poleceniem dd służy do kopiowania i konwersji danych. Schemat użycia prezentuje się następująco:
dd if=<źródło danych> of=<docelowe miejsce danych> [opcje]
Domyślne wartości if oraz of to odpowiednio: stdin i stdout. W ich miejsce można podać zarówno „zwyczajny” plik systemowy, jak i plik urządzenia (reprezentujący sterownik urządzenia, np. sterownik dysku: /dev/hda). Poniższa lista wymienia typowe komendy z wykorzystaniem dd, prezentując przy okazji popularne opcje programu.
-
utworzenie zapasowego obrazu partycji dysku pod ścieżką
~/hdadisk.img:dd if =/dev/sda2 of=~/hdadisk.img
-
skopiowanie zawartości pliku
/home/abc.txtz wyłączeniem pierwszego kilobajta do/home/xyz.txt:dd bs=1 skip=1024 if=/home/abc.txt of=/home/xyz.txt
-
wypełnienie całej partycji z wyłączeniem pierwszego kilobajta losowymi wartościami:
dd seek=2 if=/dev/random/ of=/dev/sda2
Więcej informacji na temat dd można znaleźć m.in. na tych stronach:
The Linux Juggernaut, Linux manual.
od
Kolejnego narzędzia, octal dump, będziemy używać do wyświetlania danych w formacie szesnastkowym:
od -A x -t x1 -v <ścieżka do pliku> > <ścieżka do pliku wynikowego>
Plik, do którego za pomocą instrukcji > przekierowaliśmy rezultat działania programu, przyjmie następującą postać:
[offset od początku pliku w zapisie szesnastkowym] [16 kolejnych bajtów pliku wejściowego] [>odpowiadający im zapis w ASCII<]
Jak zwykle, więcej informacji można znaleźć w manualu. Warto również zobaczyć przykłady użycia.
Alternatywnie do przeglądania plików binarnych poza MINIX-em można użyć programu hexdump:
$ hexdump -C <ścieżka do pliku> > <ścieżka do pliku wynikowego>
hexedit
Aby zainstalować program hexedit na MINIX-ie, używamy polecenia:
# pkgin install hexedit
Za pomocą tego narzędzia będziemy mogli edytować pliki binarne w bezpośredni sposób – np. zmieniając poszczególne bajty kodu maszynowego w zapisie szesnastkowym. Program oferuje dość rozbudowany interfejs, opisany m.in. na stronie autora. Na nasz użytek potrzebujemy jedynie wiedzieć, że:
- po pliku poruszamy się strzałkami,
- w celu nadpisania bajtu wystarczy ustawić kursor w jego miejscu i wpisać nową wartość,
- zmiany zapisujemy skrótem
Ctrl-w, - program zamykamy skrótem
Ctrl-c.
Hexedit jest zainstalowany w laboratorium, dlatego, zanim przystąpimy do właściwej pracy na maszynie qemu, warto od razu otworzyć dowolny plik binarny, aby oswoić się z tym programem:
$ hexedit <ścieżka do dowolnego pliku>
2.2. Podmieniamy kod maszynowy
Wyposażeni w opisany powyżej warsztat jesteśmy gotowi, aby przystąpić do wykonania pierwszych zadań.
Zadanie E1
Sprawdź, jak wygląda zapis szesnastkowy kodu boot loadera MINIX-a. Do tego celu użyj gotowego polecenia, zastępując znaki zapytania poprawnymi wartościami:
# dd bs=? count=? if=/dev/c0d0 ? od -Ax -tx1 -v
Następnie, zmieniając parametry polecenia, przyjrzyj się kilku kolejnym
sektorom za MBR, czy zostały wykorzystane przez boot loader? Czy pierwsza
partycja (/dev/c0d0p0) rzeczywiście zaczyna się dopiero w
odległości 62 sektorów od MBR?
Wyjaśnienie: w przypadku naszego obrazu MINIX-a /dev/c0d0
oznacza główny dysk twardy.
Wskazówka: sprawdź, czym różni się przekierowywanie wyników działania
programu za pomocą > (redirect) i za pomocą
| (pipe).
Wykonując pierwsze zadanie, zwróć uwagę na dwa ostatnie bajty przeglądanego sektora (pamiętając, że kolejność bajtów w tej architekturze jest zgodna ze standardem little-endian) – czy są równe magicznej wartości, która powinna znajdować się na końcu każdego boot loadera?
Zadanie E2
Napisz kod nowego boot loadera, którego jedynym zadaniem będzie wykonywanie
skoku ciągle w to samo miejsce. Zacznij od utworzenia pliku binarnego,
custom_bl, wypełnionego zerami o odpowiedniej wielkości (jak
poprzednio należy zastąpić znaki zapytania, aby uzyskać poprawne polecenie):
# dd count=? if=/dev/? of=custom_bl
Następnie:
- otwórz plik
custom_blw edytorze hexedit, - upewnij się, że jego rozmiar jest właściwy, sprawdzając pierwszą kolumnę zawierającą offset,
- zamień dwa pierwsze bajty na
eb fe– kod maszynowy instrukcji zapętlenia, - nadaj magiczną wartość dwóm ostatnim bajtom pliku.
Upewnij się, że rozumiesz, co dokładnie oznacza zapis eb fe.
Podpowiedź:
- opcode 0xeb,
- oblicz wartość reprezentowaną przez zapis
fe(pamiętając o tym, jak zapisywane są liczby ujemne).
Gotowe? Pora umieścić nasz boot loader w odpowiednim miejscu na dysku i sprawdzić, czy BIOS rzeczywiście wywoła podmieniony kod:
# dd bs=? count=1 if=custom_bl of=/dev/? # reboot
Oczywiście, bezpośrednie edytowanie kodu maszynowego nie jest ani wygodne, ani efektywne. Kolejne programy napiszemy więc w asemblerze, kompilując je następująco:
$ nasm -f bin file.asm -o file
Jak wyglądałby więc kod w asemblerze odpowiadający obecnej wersji custom_bl?
Zadanie E3
Uzupełnij linię 4 programu tak, aby po skompilowaniu, plik binarny miał wielkość 512 bajtów, a bajty między instrukcją skoku a magiczną wartością były zerami.
1: loop:
2: jmp loop
3:
4: times ? db 0;
5: dw 0xaa55
Podpowiedź: "$" w asemblerze oznacza adres, gdzie zostanie zapisana aktualna instrukcja, a symbol "$$" to adres początku bieżącej sekcji (dokumentacja NASM-a).
Skompiluj program i wyświetl zawartość binarnego pliku, używając do tego poznanych narzędzi (od albo hexedit). Wygląda znajomo, prawda?
2.3. Hello real world!
Działanie napisanego przez nas boot loadera jest na razie mało efektowne. Czy możemy zrobić cokolwiek więcej? Na etapie wykonywania kodu boot loadera nie ma przecież ani systemu plików, ani działających bibliotek, ani nawet jądra systemu operacyjnego… Czy to oznacza, że aby wypisać cokolwiek na ekranie albo odczytać z dysku, musimy sami obsłużyć odpowiednie urządzenia?
Funkcje BIOS-u
Na szczęście nie musimy sami obsługiwać podstawowych urządzeń wejścia-wyjścia.
Zajmuje się tym BIOS.
Funkcje BIOS-u wywołuje się za pomocą przerwań programowych.
Po zwięzłe i klarowne wyjaśnienie odsyłamy do rozdziału 17.2 kultowej książki The Art of Assembly Language.
Aby wywołać funkcję BIOS-u, należy wywołać przerwanie programowe za pomocą asemblerowej instrukcji int, podając numer przerwania (indeks w wektorze przerwań). Dodatkowe argumenty przekazuje się w rejestrach.
Przykładowe użycie prezentuje poniższy kod, którego zadaniem jest wypisanie na ekranie znaku 'H':
mov ah, 0xe ; argument - doprecyzowanie funkcji przerwania (wypisz znak i przesuń kursor)
mov al, 'H' ; argument - znak do wypisania
int 0x10 ; wywołanie przerwania nr 16 - obsługa ekranu
W celu sprawdzenia, jakie inne funkcjonalności udostępnia opisany mechanizm, warto przyjrzeć się liście przerwań BIOS-u.
Zadanie E4
Zmodyfikuj tak obecną wersję naszego boot loadera custom_bl.s,
aby program przed zapętleniem się wyświetlał na ekranie napis
„Hello real world!\n”. Wyjątkowo tym razem oczekujemy, że wypisywanie kolejnych
znaków zostanie zaimplementowane w stylu copy-paste.
2.4. Wywoływanie funkcji
Oczywiście, byłoby znacznie wygodniej, gdybyśmy mogli umieścić powtarzające się instrukcje w funkcji. Zdefiniujmy więc funkcję print_char w następujący sposób:
; w rejestrze al funkcja spodziewa się otrzymać argument - znak do wypisania
print_char:
mov ah, 0xe
int 0x10
ret
Z naszej funkcji korzystamy w tradycyjny sposób, czyli za pomocą instrukcji call:
mov al, 'H'
call print_char
Przypomnijmy sobie, że przy okazji wywoływania funkcji, a także przerwań, procesor korzysta ze stosu, m.in. po to, żeby zapisać w pamięci adres powrotu. Z tego powodu powinniśmy ustawić w boot loaderze swój własny stos. Inicjacja stosu wymaga:
- wybrania miejsca w pamięci, które przeznaczymy na stos,
- ustawienia rejestrów
ssisp.
Aby na obsługę stosu przeznaczyć odpowiednie adresy, musimy wiedzieć, które fragmenty przestrzeni adresowej są już zajęte (np. przez wektor przerwań, dane BIOS-u, kod naszego własnego boot loadera). Opis typowego przydziału adresów znajdziemy na wiki, które polecamy jako źródło wielu ciekawych informacji na temat budowy systemów operacyjnych. Poniżej prezentujemy przykładową inicjację stosu.
start:
xor ax, ax
mov ss, ax ; po tej instrukcji procesor blokuje przerwania na czas wykonania kolejnej instrukcji
mov sp, 0x8000 ; rejestr sp musi być załadowany natychmiast po załadowaniu rejestru ss
2.5. Odwołania do pamięci
Ostatnie usprawnienie, które omówimy, dotyczy deklarowania statycznych wartości. Przypomnijmy, że w asemblerze możemy przypisać wartość fragmentom pamięci za pomocą psuedoinstrukcji: db (declare byte), dw (declare word) i innych, o których przeczytamy w dokumentacji NASM-a. Chcąc skorzystać z tej funkcjonalności, powinniśmy upewnić się, że tryb rzeczywisty pozwoli nam swobodnie odwoływać się do adresów deklarowanych danych.
Rozważmy następujący fragment kodu:
WELCOME_MSG: db 'Hello!', 0xd, 0xa, 0x0 ; napis kończy się znakiem nowej linii (0xd, 0xa) i nullem (0x0)
BUFFER times 64 db 0 ; inicjacja 64-bajtowego bufora
start:
mov ax, BUFFER ; zapisujemy w rejestrze ax adres bufora
Jaka wartość znajdzie się w rejestrze ax?
Możesz to sprawdzić.
Skompiluj powyższy fragment kodu i otwórz plik wyjściowy programem hexedit. Znajdź instrukcję wpisywania wartości do rejestru ax (opkod 0xb8). Sąsiedni bajt to wartość (adres bufora), którą kompilator przypisze stałej BUFFER i która znajdzie się w rejestrze.
W rejestrze ax zostanie umieszczona wartość 0x9, ponieważ pierwsze 9 bajtów kodu maszynowego zajmie definicja napisu WELCOME_MSG, a domyślnym adresem załadowania programu do pamięci jest adres 0x0. Wiemy już jednak z poprzedniego punktu, że pod adresem 0x0 mieści się wektor przerwań, a kod boot loadera zwyczajowo zaczyna się od adresu 0x7c00. Musimy więc przekazać kompilatorowi informację na temat adresu, pod którym znajdzie się wygenerowany kod maszynowy, aby poprawnie policzył bezwzględne adresy, do których odwołujemy się w kodzie:
org 0x7c00 ; informacja o początkowym adresie programu ('Binary File Program Origin')
WELCOME_MSG: db 'Hello!', 0xd, 0xa, 0x0 ; napis kończy się znakiem nowej linii (0xd, 0xa) i nullem (0x0)
BUFFER times 64 db 0 ; inicjacja 64-bajtowego bufora
start:
mov ax, BUFFER ; tym razem w rejestrze ax znajdzie się wartość 0x7c09
Dodajmy teraz następującą instrukcję:
mov al, byte [WELCOME_MSG]
Oczekujemy, że w rezultacie rejestr al będzie zawierał pierwszy znak zapisany pod adresem WELCOME_MSG ('H'). Może się jednak zdarzyć, że wykonując tę instrukcję, odwołamy się do zupełnie innego adresu niż spodziewane 0x0. Jest to wynikiem segmentacji pamięci, o której była mowa w sekcji 1.1. W trybie rzeczywistym procesor interpretuje nasz kod jako:
mov al, byte ds:[WELCOME_MSG] ; ds to początek segmentu danych (data segment)
Chcielibyśmy uchronić się przed odwołaniami do niepożądanych adresów, dlatego na początku programu powinniśmy zainicjować wszystkie rejestry segmentowe (jak uczyniliśmy w przypadku rejestru ss, inicjując stos).
Nasz kod będzie odwoływał się jedynie do początkowych 64 KiB pamięci, więc wystarczy wyzerować wszystkie rejestry segmentowe.
W szczególności, wykonując daleki skok pod adres 0:start upewniamy się, że wartość rejestru cs zostanie również wyzerowana:
org 0x7c00 ; informacja o początkowym adresie programu ('Binary File Program Origin')
jmp 0:start ; wyzerowanie rejestru cs
start:
mov ax, cs ; wyzerowanie pozostałych rejestrów segmentowych
mov ds, ax
mov es, ax
mov ss, ax
mov sp, 0x8000 ; inicjowanie stosu
To wszystko, co potrzebujesz wiedzieć na tym etapie – możesz teraz śmiało przystąpić do napisania ulepszonej wersji Twojego boot loadera.
Zadanie E5
Napisz pomocniczą funkcję print, która przyjmuje adres do bufora
w rejestrze ax i wypisuje tekst z bufora aż do napotkania znaku
końca napisu (0x0).
Następnie zmodyfikuj program z zadania E4, aby używał
funkcji print do wyświetlenia „Hello real world!\n” i przetestuj
działanie nowego boot loadera.